








Лабораторна робота №14, Побудова моделі кластеризації, трасування і перехресної перевірки
Код роботи: 2518
Вид роботи: Лабораторна робота
Предмет: Інтелектуальний аналіз данних
Тема: №14, Побудова моделі кластеризації, трасування і перехресної перевірки
Кількість сторінок: 15
Дата виконання: 2017
Мова написання: українська
Ціна: 250 грн (+ програма)
Мета: розглянути побудову моделі кластеризації, трасування і перехресної перевірки
Хід роботи
Нехай необхідно провести сегментацію клієнтів Інтернет-магазину, список яких знаходиться у файлі Excel. Якщо використовувати Table Analysis Tools, для вирішення цього завдання треба застосувати інструмент Detect Categories. Також можна скористатися засобами DataMining Client for Excel, де вибрати інструмент Cluster (рис. 1).
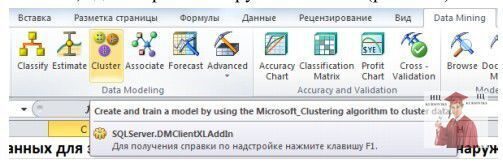
Рис. 1 - Інструмент Cluster
Відкриємо файл із зразками даних, що йде в поставці з надбудовами інтелектуального аналізу, перейдемо на лист Table Analysis Tools Sample (або можна з першого аркуша зі змістом перейти за посиланням «Зразки даних для засобів аналізу таблиць») і запустимо інструмент Cluster (рис. 2).
Перше вікно коротко описує суть завдання кластеризації і вказує на те, що для роботи майстра необхідне підключення до MS SQL Server. Наступне вікно (рис. 2-а) дозволяє вказати джерело даних - в нашому випадку це електронна таблиця Excel, після чого можна вибрати число кластерів (рис. 2-b) або вказати автоматичне визначення, а також використовувані стовпці вхідних даних. Знімемо прапорці поруч зі стовпцями ID і Purchased Bike.
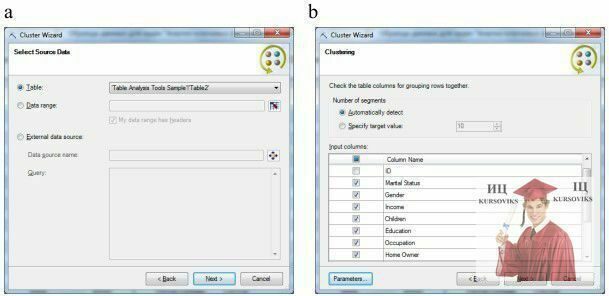
Рис. 2 - Діалогові вікна майстра кластеризації
Описаний вище вибір вхідних параметрів обумовлений тим, що стовпець з унікальним ідентифікатором покупця може тільки перешкодити алгоритму кластеризації; а чи купив клієнт велосипед чи ні, нас зараз не цікавить. Крім того, натиснувши в цьому вікні кнопку Parameters... можна отримати доступ до налаштування параметрів алгоритму кластеризації (рис. 3) і, наприклад, поміняти використовуваний за замовчуванням метод кластеризації.
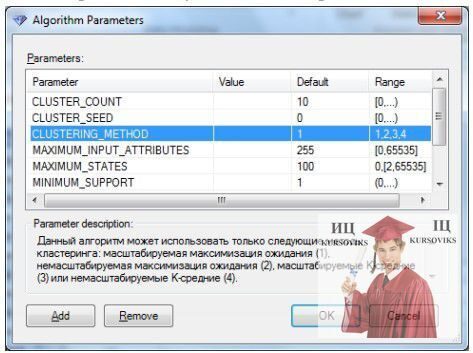
Рис. 3 - Параметри моделі кластеризації
Наступне вікно майстра дозволяє вказати відсоток даних, що резервуються для задач тестування. В останньому вікні майстра (рис. 4) можна задати ім'я структури і моделі, вказати, чи відкривати перегляд моделі, чи дозволити деталізацію, чи використовувати тимчасові моделі (за замовчуванням - ні).
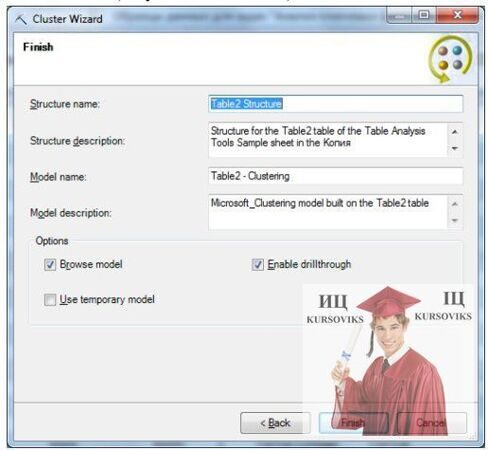
Рис. 4 - Визначення імен структури і моделі
Після натискання кнопки Finish будуть створені структура і модель, після чого модель буде оброблена і відкрита для перегляду у вікні Browser (рис. 5). Діаграма кластерів (рис. 5-a) відображає всі кластери в моделі. Заливка лінії, що з'єднує кластери, показує ступінь їх схожості. Світла або відсутня заливка означає, що кластери не надто схожі. Можна вибрати аналіз за окремим атрибутом або за всією сукупністю (Population).
Натиснувши кнопку Copy to Excel, можна отримати зображення на окремому листі таблиці Excel. Вікно Cluster Profile дозволяє переглянути розподіл значень атрибутів у кожному кластері. Наприклад, на рис. 5-b видно, що більша частина клієнтів, віднесених до кластеру 1, проживають в регіоні Europe.
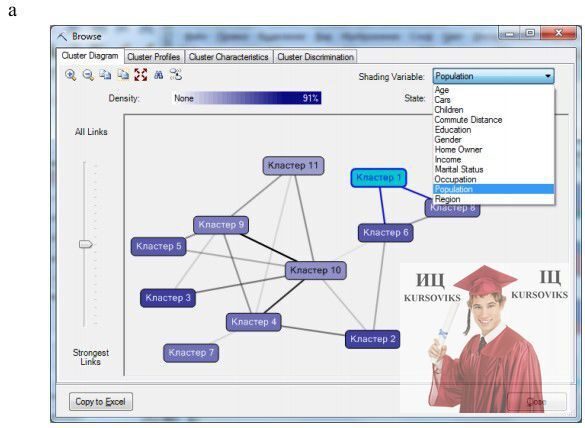
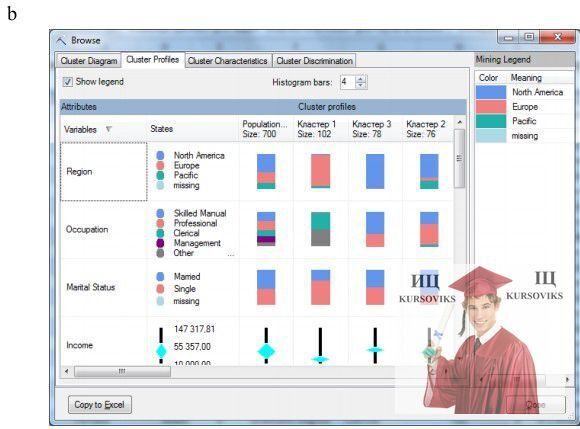
Рис. 5 - Вікна Model Browser

Рис. 5 - Вікна Model Browser (продовження)
Дискретні атрибути представлені у вигляді кольорових ліній, безперервні атрибути - у вигляді діаграми ромбів, що представляє середнє значення і стандартне відхилення в кожному кластері. Параметр Histogram bars («Стовпці гістограми») управляє кількістю стовпців, видимих на гістограмі. Якщо доступно більше стовпців, ніж вибрано для відображення, то найбільш важливі стовпці зберігаються, а ті, що залишилися групуються в сегмент сірого кольору.
У заголовку під назвою кожного кластера вказується число варіантів, які до нього віднесені. Клацнувши правою клавішею миші на заголовку стовпця, можна викликати контекстне меню, що дозволяє, зокрема, перейменувати відповідний кластер. Крім того, з контекстного меню, вибравши опцію DrillThrough Model Column, можна отримати деталізацію моделі (результати виводяться на окремий лист Excel). Наприклад, на рис. 6 показані всі варіанти, віднесені до кластеру 1.
Але повернемося до вікон Model browser. Вікно Cluster Characteristics дозволяє переглянути найбільш ймовірні значення атрибутів для всієї множини варіантів (Population) і для кожного кластера (якщо вибрати кластер у випадаючому списку). В останньому випадку, стовпці сортуються за ступенем важливості даного атрибута для кластера. Наприклад, в розглянутому вище кластері 1, на першому місці буде знаходитися атрибут Region зі значенням Europe. При цьому, ймовірність того що клієнт, віднесений алгоритмом до цієї категорії, проживає саме в Європі, оцінюється як дуже висока.
Вікно Cluster Discrimination дозволяє провести попарне порівняння двох кластерів (рис. 5-d) або вибраного кластера і всіх інших варіантів.
Тепер перейдемо до аналізу того, що ж відбувається на сервері. У цьому допоможе інструмент Trace, розташований в Data Mining в розділі Connection. Якщо натиснути цю кнопку, відкриється вікно, в якому відображається вміст запитів, що відправляються на сервер (рис. 7).

Рис. 6 - Результати деталізації моделі
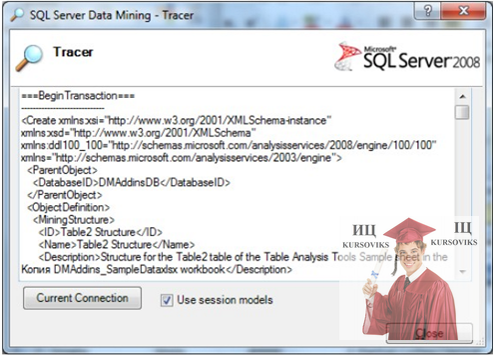
Рис. 7 - Вікно трасування
Якщо проаналізувати текст запитів, видно, що перша частина - це опис у форматі XML створюваної структури і моделі. Друга частина, яка наводиться нижче - це DMX запит на заповнення та обробку структури і всіх її моделей.
INSERT INTO MINING STRUCTURE [ Table2 Structure ]
( RowIndex,
[ Marital Status ], [ Gender ],
[ Income ], [ Children ],
[ Education ],
[ Occupation ],
[ Home Owner ], [ Cars ],
[ Commute Distance ], [ Region ],
[ Age ]) @ ParamTable ParamTable =
Microsoft.SqlServer.DataMining.Office.Excel.ExcelData Reader
Використання трасування дозволяє глибше розібратися в особливостях роботи надбудов інтелектуального аналізу, а при виникненні помилок виявити їх причини.
Завдання 1. За аналогією з розглянутим прикладом створіть модель кластеризації. Вивчіть і проаналізуйте отримані результати. Відрийте вікно трасування, проаналізуйте запити які відправляються на сервер.
Тепер розглянемо інструмент перехресної перевірки Cross-Validation (перехресна перевірка доступна при використанні SQL Server версії Enterprise або Developer). Суть її полягає в тому, що безліч варіантів, які використовує модель, розбивається на непересічні підмножини (розділи). Для кожного з розділів проводиться обробка моделі та отримані результати порівнюються з тими, що були на початковій множині варіантів. Якщо результати близькі, можна говорити про вдалу модель інтелектуального аналізу: вихідних даних вистачило, результат прогнозу чи аналізу досить стабільний.
У розділі Accuracy and Validation виберемо інструмент Cross- Validation. Перше вікно майстра повідомляє про суть виконуваної перевірки. У другому вікні (рис. 8) проводиться вибір моделі для перехресної перевірки. Вкажемо нашу модель кластеризації - Table2 - Clustering.
Після вибору моделі потрібно вказати параметри проведеної перехресної перевірки. Зокрема, вказується число розділів з даними для перехресної перевірки (Fold Count, за замовчуванням 10), максимальне число варіантів, що використовується при перевірці (значення Maximum Rows = 0 вказує на те, що будуть використовуватися всі; якщо вихідних даних багато, при використанні всіх даних перехресна перевірка може зайняти тривалий час), цільовий атрибут (Target Attribute).
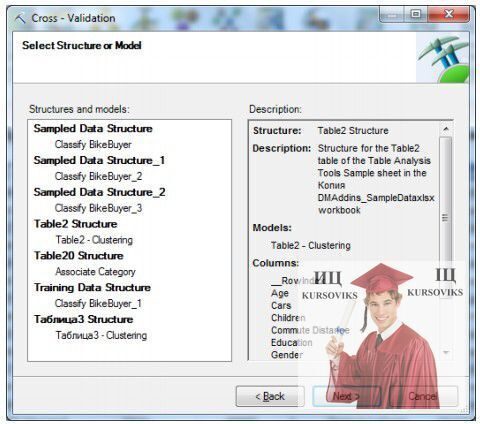
Рис. 8 - Вибір моделі для перехресної перевірки
На рис. 9 в якості цільового атрибута (англ. Target Attribute) вибраний #Cluster, це номер кластера, до якого належить варіант. Суть перевірки буде полягати в тому, що виконується кластеризація в рамках окремого розділу і отриманий номер кластера, до якого віднесено варіант, буде порівнюватися з номером кластера, отриманим при обробці моделі з використанням всієї множини варіантів. Збіг говорить про те, що модель хороша (правильно визначені наявні шаблони).
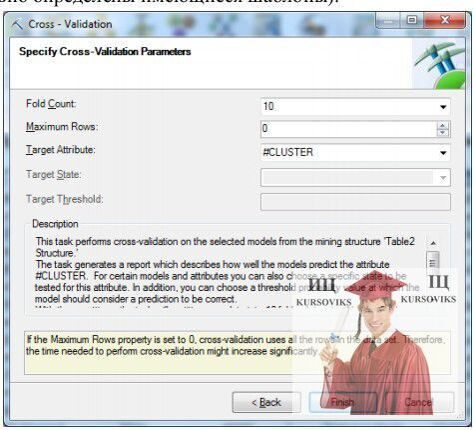
Рис. 9 - Вказівка параметрів перехресної перевірки
За результатами виконання перехресної перевірки формується звіт (рис. 10). У ньому показується, скільки варіантів використовувалося для перевірки (на малюнку - 700), які розділи були сформовані (у нашому прикладі 10 розділів по 70 рядків даних), результати проведеного аналізу. На рисунку видно, що в середньому, результати, отримані при аналізі по розділах, більш ніж в 82 % випадків збігаються з результатами вихідної моделі. Невеликий розкид значень для різних розділів, вказує на стабільність одержуваного результату, тобто побудована модель інтелектуального аналізу може бути визнана вдалою.
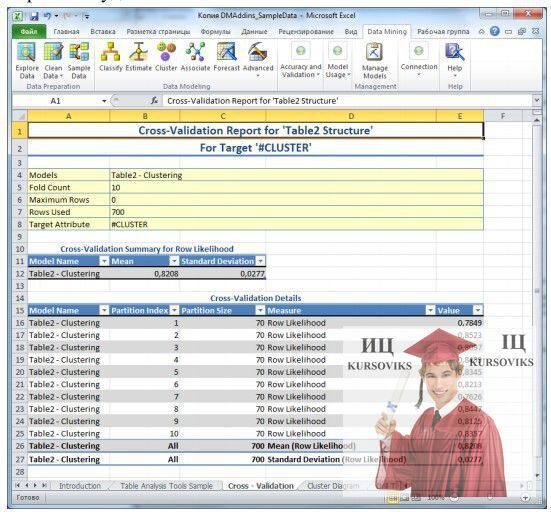
Рис. 10 - Звіт за результатами перевірки
Завдання 2. Виконайте перехресну перевірку для створеної моделі інтелектуального аналізу. Опишіть і проаналізуйте отримані результати.