








Лабораторна робота №13, Аналіз точності прогнозу та використання моделі інтелектуального аналізу
Код роботи: 2517
Вид роботи: Лабораторна робота
Предмет: Інтелектуальний аналіз данних
Тема: №13, Аналіз точності прогнозу та використання моделі інтелектуального аналізу
Кількість сторінок: 20
Дата виконання: 2017
Мова написання: українська
Ціна: 250 грн (+ програма)
Мета: розглянути аналіз точності прогнозу та використання моделі інтелектуального аналізу
Хід роботи
У лабораторній роботі ми створили модель для класифікації клієнтів магазину з метою визначити, чи зробить даний клієнт покупку чи ні. Наступне завдання - оцінити точність побудованої моделі інтелектуального аналізу. Для цього можна використовувати інструменти з групи Accuracy and Validation (Точність і Правильність).

Рис. 1 - Інструменти Data Mining Client
Діаграма точності (англ. Accuracy Chart) дозволяє, застосувавши модель на тестовій вибірці даних, оцінити результати її роботи. У ході виконання попередніх лабораторних роботах була створена структура Training Data Structure і модель класифікації Classify BikeBuyer_1. При створенні моделі ми резервували 30 % даних для цілей тестування (рис. 5.65- a).
Запустимо інструмент Accuracy Chart. Перше вікно майстра містить короткий опис інструменту, в наступному - треба вказати структуру або модель (рис. 2-a). Якщо для однієї структури визначені кілька моделей, по діаграмі можна буде провести їх порівняльний аналіз. Наступне вікно (рис. 2-b) служить для вибору прогнозованого параметра і його значення. У нашому випадку параметр - BikeBuyer, а оцінювати будемо точність передбачення значення «Yes». Далі потрібно вказати джерело даних для тестування. Це можуть бути зарезервовані при створенні моделі даних, дані з таблиці або діапазону комірок Excel, або із зовнішнього джерела (рис. 2-c). Зараз виберемо дані з моделі. У випадку зазначення таблиці Excel, треба описати відповідність стовпців в моделі і таблиці, що використовується для тестування (рис. 2-d). Після цього будуть сформовані і поміщені на новий аркуш Excel діаграма точності (рис. 3) і таблиця зі значеннями, представленими на діаграмі (рис. 4).
На діаграмі верхня лінія відповідає ідеальній моделі, середня - нашій моделі, нижня - лінія випадкового вибору, завжди йде під кутом 45 градусів.

Рис. 2 - Майстер побудови діаграми точності

Рис. 3 - Діаграма точності (Accuracy Chart)

Рис. 4 - Фрагмент таблиці з оцінками точності прогнозу
Дані на діаграмі і в таблиці можна інтерпретувати так. Нехай нам необхідно вибрати всіх клієнтів, які зроблять покупки. Сформована ідеальною моделлю вибірка обсягом у 11 % від числа початкових записів включатиме всі 100 % потрібних записів (в тестовій множині їх трохи менше 11 %). Випадкова вибірка обсягом у 11 % містить 11 % потрібних записів, а вибірка такого ж об'єму, сформована нашою моделлю - 26,58 %. У вибірку в 25 % від загального обсягу даних, наша модель помістить 52,7 % «правильних» клієнтів і т.д. Якість прогнозу падає (горизонтальна ділянка графіка Classify BikeByer_1) після виявлення 76 % випадків які нас цікавлять. При візуальному аналізі - чим ближче графік оцінюваної моделі до ідеального, тим точніший прогноз вона видає.
Завдання 1. Побудуйте діаграму точності аналогічну тій, що представлена вище (використовуваний файл - «Зразки даних Excel»). Додатково побудуйте діаграму для BikeBuyer = «No». Поясніть відмінності в зовнішньому вигляді графіків.
Завдання 2. У попередньому завданні для цілей тестування використовувалися дані з моделі. Модель формувалася на даних з таблиці Training Data. У таблиці Testing Data знаходяться 30 % даних з початкового набору Source Data. Перевірте точність моделі на наборі Testing Data.
Аналізуючи графік на рис. 3 можна припустити, що з моделлю все добре, і прогноз робиться досить точно. Але звернемося до ще одного інструменту аналізу точності - Classification Matrix (Матриця класифікації). За його допомогою ми отримуємо таблицю з результатами точних і помилкових прогнозів (рис. 5).

Рис. 5 - Матриця класифікації
Аналіз матриці показує, що створена нами модель при тестуванні на зарезервованих даних зробила 89,43 % правильних прогнозів, що можна розцінити як успіх (тому й діаграма точності на рис. 3 виглядає добре). Але при цьому в 100 % випадків вона правильно прогнозувала значення «No» і помилково «Yes». Інакше кажучи, завжди ставиться «No». І використовувати таку модель для передбачення безглуздо.
Завдання 3. Побудуйте матрицю класифікації, проаналізуйте отриманий результат.
Проблема, з якою ми зіткнулися, могла бути виявлена і раніше, якщо уважно подивитися на побудоване дерево рішень (рис. 6). Але тоді не вдалося б продемонструвати можливості інструментарію Data Mining по оцінці точності моделі.
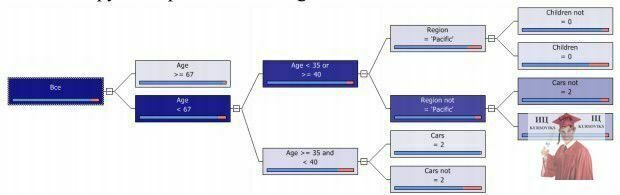
Рис. 6 - Дерево рішень
З рис. 6 видно, що всі кінцеві вузли дерева дають рішення BikeBuyer= «No» (йому відповідає синя смужка на діаграмі, що характеризує розподіл відповідей в навчальній вибірці). Відповіді «Yes» відповідає більш коротка червона смужка, що говорить про те, що прикладів які підтримують такий результат було менше. Це пов'язано з тим, що таких прикладів меншість в даному наборі даних (близько 10 %).
Спробуємо використовувати навчальний набір більшого обсягу і зі значенням, що більш часто зустрічається BikeBuyer = «Yes». Відкриємо таблицю Source Data, де даних більше. Але відсоток записів, що нас цікавлять залишається таким же (це можна визначити за допомогою інструменту Explore Data). Тому скористаємося інструментом Sample Data, щоб сформувати «надлишкову» вибірку з 2000 рядків, де в 30 % випадків BikeBuyer = «Yes». В отриманому наборі залишимо автоматично призначену назву Sampled Data. За допомогою інструменту Classify побудуємо модель аналогічну тій, як це було зроблено в лабораторній роботі (алгоритм - DecisionTrees, цільовий параметр BikeBuyer, стовпець ID при аналізі не враховуємо, інші настройки - за замовчуванням). Отримане дерево рішень представлено на рис. 7. Воно простіше попереднього, але залежно від значень параметрів може давати як прогноз «Yes», так і «No». «Yes» буде в тому випадку, якщо у клієнта 0 машин і він з регіону «Pacific».

Рис. 7 - Нове дерево рішень
На основі нового набору даних створимо також модель для класифікації, засновану на алгоритмі Neural Networks (нейронних мереж). Якщо побудувати для моделей матриці класифікації (рис. 8) буде видно, що модель на основі нейронних мереж дає більш точний прогноз.
Розглянутий приклад показує, що в деяких випадках точність прогнозу можна підвищити за рахунок спеціальної підготовки навчальної вибірки і вибору алгоритму, який нам найбільш походить. Хоча, враховуючи відносно високий відсоток помилок, ні та, ні інша модель, напевно, не може бути визнана дуже вдалою.
Завдання 4. Проведіть описані в роботі дії. Прокоментуйте результати.

Рис. 8 - Матриці класифікації для дерева рішень (a) і нейронних мереж (b)
Запити до моделі
Тепер перейдемо до побудови запиту до моделі інтелектуального аналізу. На сервері є модель, визнана придатною для прогнозування. У використовуваному нами файлі Excel з даними для інтелектуального аналізу є таблиця New Customers з інформацією про нових клієнтів (рис. 9).
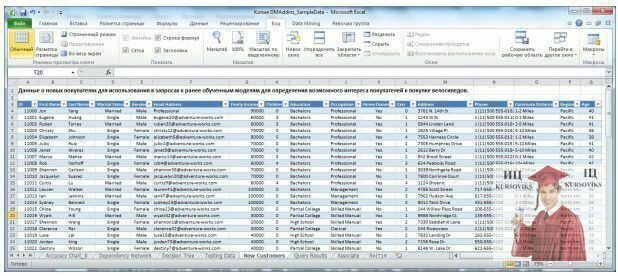
Рис. 9 - Таблиця New Customers
У таблиці New Customers є всі стовпці, які були в наборі Source Data, крім стовпця BikeBuyer (це нові клієнти, і ми не знаємо, чи зроблять вони покупку), крім того, є ряд несуттєвих для аналізу нових параметрів - ім'я, адреса електронної пошти, телефон і т.д. Наше завдання полягає в тому, щоб передбачити, хто з цих людей готовий зробити покупку.
Запускаємо інструмент Query (група Model Usage, рис. 1) і вибираємо використовувану модель інтелектуального аналізу (рис. 10-a). Після цього вказуємо джерело даних, для якого треба провести аналіз. У нашому випадку це таблиця «New Customers» (рис. 10-b). Наступне вікно дозволяє вказати відповідність параметрів моделі і стовпців таблиці. У нашому випадку нічого виправляти не буде потрібно (рис. 10-c). Далі визначаємо вихідне значення, тобто стовпець, який міститиме прогноз. У вікні «Choose Output» (аналогічному рис. 10-e, тільки без вихідного значення), натискаємо кнопку «Add Output» і отримуємо можливість визначити вихідний стовпець (рис. 10-d). Назвемо його «Буде купувати». Залежно від того, куди буде виводитися результат роботи (у вихідну таблицю, на новий аркуш Excel і т.д.), може знадобитися включити у вихідний набір додаткові стовпці (ідентифікатор клієнта і т.д.). Після додавання вихідних параметрів (рис. 10-e) треба вказати, куди буде виводитися результат. За замовчуванням (рис. 10-f) результат буде поміщений в таблицю з вихідними даними, але можна зажадати висновок на новий або вже існуючий лист Excel.
У ході роботи у вікнах 10-a - 10-e можна натиснути кнопку Advanced і потрапити у вікно конструктора запиту на мові DMX (рис. 11). Тут можна переглянути або поправити згенерований код запиту на DMX, який буде передано Аналітичним Службам MS SQL Server 2008.
В результаті виконання сформованого майстром запиту у вихідну таблицю буде додано стовпець, що містить результати виконаної класифікації (рис. 12).



Рис. 10 - Побудова запиту

Рис. 11 - Конструктор запитів

Рис. 12 - У вихідну таблицю доданий стовпець з результатами роботи
Завдання 5. Виконайте запит до моделі інтелектуального аналізу. Оцініть отримані результати.