








Лабораторна робота №9, Використання інструментів Analyze Key Influencers і Detect Categories
Код роботи: 2513
Вид роботи: Лабораторна робота
Предмет: Інтелектуальний аналіз данних
Тема: №9, Використання інструментів Analyze Key Influencers і Detect Categories
Кількість сторінок: 12
Дата виконання: 2017
Мова написання: українська
Ціна: 250 грн (+ програма)
Мета: розглянути використання інструментів "Analyze Key Influencers" і "Detect Categories"
Хід роботи
Почнемо безпосереднє вивчення інструментів інтелектуального аналізу даних (DataMining, скор. DM). До складу пакету надбудов для MS Office 2007 входить електронна таблиця із зразками даних. Вона може бути відкрита з меню Пуск->Надстройки интеллектуального анализа данных Microsoft SQL Server 2008.
Відкрийте файл «Введение в Data Mining.xls» і відформатуйте дані на аркуші "Средства анализа таблиц" як таблицю (див. Лабораторну № 1). Перейдіть на вкладку Analyze (Анализировать) (рис. 1). Ця таблиця містить дані фірми, що продає велосипеди. У ній зібрано інформацію про клієнтів (ідентифікатор, сімейний стан, стать і т.д.) і зазначено, придбав клієнт велосипед чи ні.
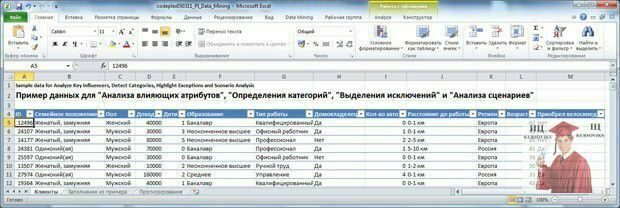
Рис. 1 - Підготовлений набір даних
Аналіз ключових факторів впливу
Інструмент AnalyzeKeyInfluencers (Анализ ключевых факторов влияния) дозволяє визначити, як залежить параметр який для нас цікавий від інших. При цьому важливо правильно визначити, що і від чого може залежати. Власне в цьому частково і полягає майстерність аналітика, заснована на його знанні предметної області і використовуваних методів DM. У зв'язку з тим, що ми оцінюємо ступінь взаємного впливу різних параметрів один на одного, варто відразу прибрати з розгляду повністю незалежні і навпаки, повністю залежні. Нехай, наприклад, ми хочемо оцінити вплив різних чинників на рівень заробітної плати людини. Якщо у нас є поле, що містить унікальний ідентифікатор (наприклад, порядковий номер запису в таблиці або номер паспорта), його варто прибрати з розгляду, як що не впливає на значення досліджуваного параметра. Інший приклад, нехай у нас є значення заробітної плати за місяць і за рік, що розраховується як заробітна плата за місяць, помножена на 12. Ми знаємо, що ці значення завжди пов'язані, шукати залежність одного від іншого засобами DM не має сенсу, а наявна сильна залежність приховає вплив інших факторів, який ми якраз і хочемо виявити.
Тепер визначимо, від чого залежить рішення клієнта про покупку велосипеда. Натискаємо на кнопку AnalyzeKeyInfluencersі вказуємо в якості цільового стовпця стовпець "Приобрел велосипед" (рис. 2). Перейдемо за посиланням "Choosecolumnstobeusedforanalysis", щоб вказати параметри, вплив яких ми хочемо оцінити (рис. 3). Тут скинемо позначку навпроти "ID" і "Приобрел велосипед" (хоча останнє можна і не робити).

Рис. 2 - Вибір залежного параметра для аналізу

Рис. 3 - Вибір параметрів, від яких залежить аналізований
Після запуску процедури аналізу (по кнопці Run, рис. 2) буде сформовано звіт про фактори впливу та запропоновано формування додаткового порівняльного звіту (рис. 4). В основному звіті вказується стовпець (Column), його значення (Value), значення цільового стовпця, з яким воно пов'язується (Favors) рівень впливу (Relative Impact), оцінюваний за шкалою від 0 до 100 балів. З представленого на рис. 4 звіту видно, що на рішення не купувати велосипед найбільшою мірою впливає наявність 2 -х автомобілів. У той же час не слід сприймати оцінку 100 балів, як ознака того, що в 100 % випадків власники 2 -х машин велосипед не купували (подивіться набір даних, там є і поєднання "2 машини - велосипед куплений", але їх меншість). Другий за рівнем впливу на відмову від покупки фактор - "Сімейний стан" = "жонатий, заміжня".
Найбільший вплив на позитивне рішення про придбання велосипеда надає відсутність у клієнта машини.
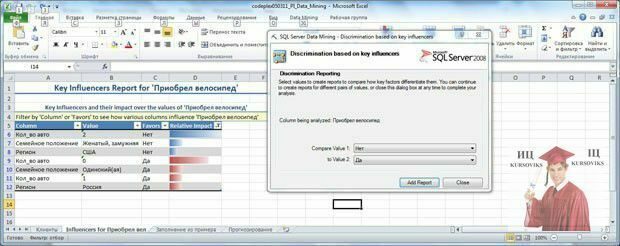
Рис. 4 - Основний звіт

Рис. 5 - Порівняльний звіт
Якщо додати порівняльний звіт для двох обраних значень (рис. 4, Add Report), можна побачити, чим відрізняється вибір на користь одного значення цільового стовпця від вибору на користь іншого (рис. 5). У нашому прикладі просто відбудеться перегрупування вихідного звіту, так як можливих значень всього 2. В інших випадках, додатковий звіт дозволяє провести детальне порівняння двох обраних варіантів.
Якщо цільовий або інший стовпець, оброблюваний інструментом Analyze Key Influencers, містить багато різних числових значень, то проводиться дискретизація. Весь інтервал значень ділиться на декілька діапазонів, кожен з яких розглядається як одне з можливих значень (наприклад, замість точного значення 2,5 ми отримаємо "діапазон від 2 до 3").
Завдання 1. Проведіть аналіз відповідно до розглянутого прикладу.
Завдання 2. На тому ж наборі даних проаналізуйте залежність рівня доходу від освіти, сімейного стану, типу роботи, статі, віку та регіону проживання клієнта. Опишіть результати.
Доповніть звіт порівняльним аналізом для самого низького і наступного за ним діапазону доходу. А потім - для найнижчого і самого високого діапазону. Опишіть результати проведеного аналізу та запропонуйте їх інтерпретацію.
Завдання 3. Запропонуйте свій варіант аналізу даних, і приклад використання отриманих результатів.
Сформований звіт буде доступний і у випадку, якщо ви відкриєте файл і на іншому комп'ютері (без підключення до аналітичних служб SQL Server). Щоб повернути дані в початковий стан потрібно видалити аркуші зі сформованими звітами.
Виявлення категорій
Інструмент Detect Categoriesдозволяє вирішити завдання кластеризації, тобто поділу всієї множини варіантів на "природні" групи, члени яких найбільш близькі по ряду ознак. Подібна задача також називається завданням сегментації.
Отже, в нашому прикладі є опис безлічі клієнтів і потрібно розділити їх на невелику кількість груп (щоб окремим групам сформувати спеціальну пропозицію і т.п.).
У зв'язку з тим, що в процесі роботи інструмент додає дані у вихідну таблицю, рекомендується перед початком роботи зробити її копію (рис. 6).
Після цього натискаємо кнопку Detect Categoriesі налаштовуємо параметри (рис. 7). Тут хочеться звернути увагу на атрибут ID, який як було зазначено вище, не можна буде враховувати у ході аналізу. Тому він автоматично виключений. У нашому випадку, інші атрибути можна залишити. Ще раз хотілося б повторити, що цей вибір кожен раз робиться виходячи з особливостей предметної області.

Рис. 6 - Перед початком роботи краще скопіювати лист Excel

Рис. 7 - Вибір параметрів, які будуть аналізуватися
Крім вказівки врахованих параметрів, можна явно вказати число категорій (або залишити за замовчуванням автоматичне визначення). Також за замовчуванням поставлений прапорець "Appenda Category column to the original Excel table", який вказує, що до записів у вихідній таблиці буде додано вказівку на категорію.
Сформований звіт містить 3 розділи. У першому зазначено певні категорії і число рядків, що потрапляють в кожну з них (рис. 8). Поле з назвою категорії допускає редагування і можна зіставити категорії більш значущу назву. Наприклад, як буде показано нижче, для клієнтів першої категорії характерний низький дохід і її можна так і назвати. Коли ми введемо це назву, скрізь крім діаграми Category Profiles Chat, воно автоматично замінить "Category 1" (щоб назву поміняти і на діаграмі, треба натиснути <Alt>+<Ctrl>+<F5>).

Рис. 8 - Виділені категорії
Наступний розділ звіту описує характеристики виділених категорій і ступінь впливу кожного параметра (рис. 9). За замовчуванням відображається інформація тільки по одній категорії, але клацанням миші по іконці фільтра на заголовку таблиці можна встановити відображення всіх категорій або якогось їх поєднання, як це показано на рис. 9.

Рис. 9 - Опис категорії
Третій розділ звіту - це діаграма профілів категорій. Вона показує кількість рядків даних у кожній категорії з кожним значенням вибраних параметрів. За замовчуванням відображається тільки один параметр. Для розглянутого прикладу це вік. Але в нижній частині діаграми є фільтр Column, за допомогою якого можна змінити число параметрів. Наприклад, на рис. 10 для кожної категорії відображається розподіл за віком та доходом. З нього видно, що клієнти перейменованої нами категорії "Низкий доход" насправді мають дуже низький дохід. А клієнти категорії 3 в переважній більшості дуже молоді.

Рис. 10 - Діаграма профілів категорій

Рис. 11 - Зіставлення категорій записам у вихідній таблиці
Рис. 11 показує, що всім записам вихідної таблиці тепер співставлена категорія, до якої вони належать. А за допомогою фільтрів можна переглянути записи, які стосуються обраної категорії.
Завдання 1. Перейменуйте категорію Category 3.
Завдання 2. Проведіть аналіз параметрів, що характеризують залишилися категорії, і дайте їм осмислені назви.