








Лабораторна робота №7, Використання інструментів Data Mining Client для Excel 2007 для підготовки даних
Код роботи: 2511
Вид роботи: Лабораторна робота
Предмет: Інтелектуальний аналіз данних
Тема: №7, Використання інструментів Data Mining Client для Excel 2007 для підготовки даних
Кількість сторінок: 20
Дата виконання: 2017
Мова написання: українська
Ціна: 250 грн (+ програма)
Хід роботи
Розглянуті в попередніх лабораторних роботах "Засоби аналізу таблиць для Excel" (Table Analysis Tools) дозволяють швидко провести "стандартний" аналіз наявних даних. Водночас, цей набір інструментів не надає особливих можливостей з підготовки даних до аналізу, оцінці результатів і т.д. З Excel це можна зробити, використовуючи клієнт інтелектуального аналізу даних (Data Mining Client), який також входить в набір надбудов інтелектуального аналізу. У ході лабораторної роботи № 1, зазначалося, що бажано зробити повну установку надбудов, в яку входить і Data Mining Client.
1. Відкриємо набір даних який вже використовувався нами, що входить в постачання надбудов (меню Пуск, знайдіть Надстройки интеллектуального анализа даннях -> Образцы данных Excel). Щоб можна було спокійно вносити зміни, краще зберегти його під новим іменем. Перейдіть на лист "Исходные данные" (Source Data) і клацніть на закладці DataMining. Стрічка із пропонованими інструментами представлена на рис. 1.
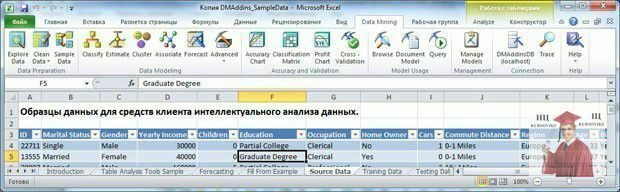
Рис. 1 - Інструменти Data Mining Client
Перша група інструментів (Data Preparation - Подготовкаданных), дозволяє провести перше знайомство з набором даних і підготувати його для подальшого аналізу.
Інструмент Explore Data дозволяє проаналізувати значення стовпця (або діапазону комірок) і відобразити їх на діаграмі. Розглянемо його роботу на прикладі значення річного доходу клієнта (Income). Додатковий інтерес становить те, що це значення може розглядатися і як безперервне, і як дискретне. Отже, запускаємо інструмент Explore Data (рис. 2).

Рис. 2 - Інструмент Explore Data
У процесі роботи буде потрібно вказати, для якої таблиці (або діапазону комірок) і стовпця проводитиметься аналіз (рис. 2-1 і рис. 2-2). Після чого зазначені значення будуть проаналізовані і результат буде представлений у вигляді гістограми.
Як вже зазначалося вище, значення річного доходу можна розглядати і як безперервне, і як дискретне (за рахунок того, що в нашому наборі даних присутні тільки значення, кратні 10 тисячам). Для безперервного значення буде запропонований варіант розбиття на діапазони (рис. 2-3). Число діапазонів можна поміняти і діаграма з розподілом значень буде побудована заново. Натиснувши кнопку "Add New Column" можна додати у вихідну таблицю новий стовпець з інтервалами річного доходу.
Наприклад, якщо для рядка значення Yearly Income = 30000, то значення нового параметра Yearly Income 2 при використанні представленого на рисунку розбиття буде "'30000 - 50000" (саме так, з апострофом на початку, щоб розглядалося як рядкове). У ході інтелектуального аналізу, отриманий стовпець може використовуватися замість вихідного (включення обох стовпців одночасно небажано).
Кнопками із зображеннями графіка і гістограми (на рис. 2-3, рис. 2-4 вони підкреслені), можна вказати тип аналізованого значення - безперервне або дискретне. Якщо значення річного доходу розглядаємо як дискретне, то для нього буде побудована діаграма, що показує розподіл числа рядків за значенням річного доходу (рис. 2-4). При цьому сортування проводиться за спаданням кількості рядків з даних значенням, через що перший стовпець гістограми відповідає значенню "60000", другий - "40000" і т.д. Сформовану гістограму можна скопіювати в буфер (кнопка правіше кнопки "Add New Column", рис. 2-3, рис. 2-4) і використовувати для подальшої роботи.
Інструмент Clean Data(рис. 3) дозволяє підготувати дані для аналізу, відкинувши нетипові або помилкові дані (викиди), а також провівши заміну окремих значень. Як наголошується в документації, під викидом мається на увазі значення даних, що є проблематичним по одній з наступних причин:
- значення знаходиться за межами очікуваного діапазону;
- дані були введені неправильно;
- значення відсутнє;
- дані представляють собою пропуск або порожній рядок;
- значення може значно відхилитися від розподілу, якому підпорядковуються дані в моделі.
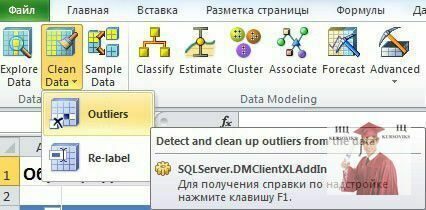
Рис. 3 - Інструмент Clean Data
Використання даного інструменту проілюструємо на прикладі тієї ж самої таблиці з даними про клієнтів (лист Source Data). Звернемося до колонки з віком. Нехай нам потрібно очистити набір даних від інформації про нехарактерних за віком покупцях. Запускаємо інструмент Clean Data -> Outliers, у вікні аналогічному представленому на рис. 2-1 вибираємо таблицю для аналізу, потім у вікні Select Column(рис. 2-2) - стовпець Age.
У розглянутому наборі даних є рядки зі значеннями стовпця Ageвід 25 до 96 років. Якщо цей параметр вважаємо безперервним, то він буде представлений графіком, де по осі X вказується вік, по осі Y - число клієнтів з таким віком. У наборі даних частка клієнтів похилого віку дуже мала. На рис. 4-1 показано, що встановивши граничне значення в 75 років, ми відкидаємо заштрихований "хвіст", що включає нехарактерні значення (покупці велосипедів у віці від 76 до 96 років, яких переважна меншість).
Багато в чому аналогічно виглядає робота з параметром, приймаючим дискретні значення. Для нього будується гістограма, а для визначення порогу потрібно вказати мінімальне число прикладів, що "підтримують" значення. Наприклад, на рис. 4-2, встановлено граничне значення в 15. На жаль, при великому числі стовпців гістограми, значення параметра на ній не відображаються. Тому не зрозуміти, що саме потрапляє в "хвіст" розподілу.

Рис. 4 - Використання інструменту Clean Data для виключення викидів
Отже, ми виділили нехарактерні дані. Тепер потрібно визначити, що з ними робити. Запропоновані майстром рішення дещо відрізняються для випадків безперервного і дискретного параметра. Відповідний рядок можна видалити (Delete rows containing outliners) або замінити значення параметра на порожнє (Change value to null). Крім того, для безперервних даних (рис. 2-3) можна замінити нехарактерне значення середнім або граничним (зверху чи знизу, залежно від того, який діапазон відкидається). Для дискретного параметра (рис. 2-4) можна вказати значення (з числа вже наявних в наборі), на яке будуть замінюватися "викиди".
Останнє вікно майстра (воно на малюнку не представлено) пропонує вибрати, куди заносити зміни - у вихідні дані (Changedatainplace), в їх копію на новому аркуші Excel (Copysheetdatawithchangestoanewworksheet) або в новий стовпець у вихідній таблиці (Addasanewcolumntothecurrentworksheet). Остання опція для випадку видалення рядків недоступна.
У деяких випадках у вихідних даних можуть бути значення, які ускладнюють автоматизований аналіз. Наприклад, є параметр "місто" і серед його значень - Санкт-Петербург, С-Петербург, СПб. Для того, щоб у процесі інтелектуального аналізу ці значення враховувалися коректно, треба їх замінити на одне. Для цього можна використовувати інструмент Re-label. Його ж можна застосувати, якщо потрібно знизити рівень деталізації значень параметра. Треба відзначити, що інструмент працює тільки з дискретними значеннями (ну або ж розглянутими як дискретні).
Для прикладу, в таблиці з інформацією про клієнтів нам треба зменшити число значень параметра Commute Distance(відстань щоденних поїздок). Вихідні значення "0-1 Miles", "1-2 Miles", "2-5 Miles", "5-10 Miles", "10 + Miles". Нехай все, що менше 2 миль, буде "близко", інше - "далеко". Додамо в таблицю два порожні рядки і вкажемо для одного Commute Distance"близко", для іншого - "далеко". Робиться це тому, що значення, на які ми замінюємо, теж повинні бути присутніми в стовпці.
Запустимо інструмент: CleanData -> Re-label. Перші два екрани, як і раніше, дозволяють вказати таблицю і стовпець. Далі вказуємо порядок заміни (рис. 5-1) і вибираємо створення нового стовпця (рис. 5-2), щоб не втратити вихідні дані. Заміна буде проведена, після чого не забудемо видалити додані порожні рядки з "близко" - "далеко".
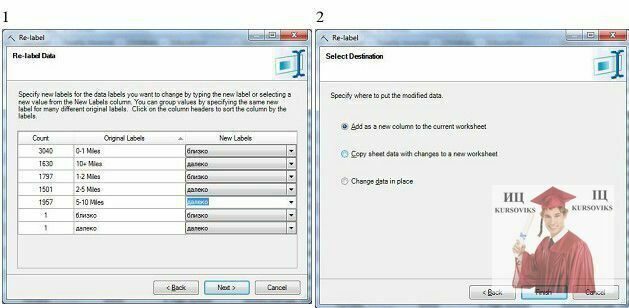
Рис. 5 - Заміна позначень
Останній інструмент в групі Data Preparationназивається Sample Data(зразки даних). Він дозволяє вирішити задачу формування навчаючої і тестової множин даних, а також виконувати "балансування" даних.
У тих випадках, коли використовуваний метод інтелектуального аналізу вимагає попереднього навчання моделі (наприклад, для вирішення завдання класифікації) необхідно сформувати кілька наборів даних - для навчання моделі, перевірки її роботи, власне аналізу. Інструмент Sample Dataдозволяє підготувати потрібні набори.
Нехай необхідно випадковим чином розділити наявний набір даних на навчальну і тестову вибірку. Для цього треба запустити інструмент Sample Data, вказати звідки беремо дані для обробки (рис. 6-1) і тип сформованої вибірки. Спочатку зробимо випадкову вибірку, тобто тип - Random Sampling(рис. 6-2). Далі вказується відсоток записів з вихідного набору (або точне число записів) які поміщаються у вибірку (рис. 6-3) і місце для збереження отриманих результатів. На рис. 6-4 видно, що можна окремо зберегти сформовану вибірку і дані, в неї не потрапили. У підсумку можемо отримати навчальний і тестовий набори. Хотілося б звернути увагу на можливість використання зовнішнього джерела даних при формуванні вибірки (рис. 6-1).
Це дозволяє використовувати дані, що зберігаються на MS SQL Server для формування наборів значень. Але як наголошується в описі інструменту, при використанні зовнішнього джерела даних у вікні, представленому на рис. 2, буде доступний тільки параметр випадкової вибірки.
При використанні засобів інтелектуального аналізу для виявлення рідкісних подій, в навчальному наборі рекомендується збільшити частоту появи потрібної події у порівнянні з вихідними даними. Формування подібної вибірки часто називають балансуванням даних, і інструмент Sample Dataдозволяє її виконати.
За допомогою інструменту Explore Dataпроаналізуємо розподіл клієнтів в наборі даних по регіонах. На рис. 7-1 видно, що приблизно п'ята частина клієнтів у нас з регіону Pacific(будемо вважати це Азіатсько- Тихоокеанським регіоном). Сформуємо набір даних, де таких клієнтів буде 50 %.
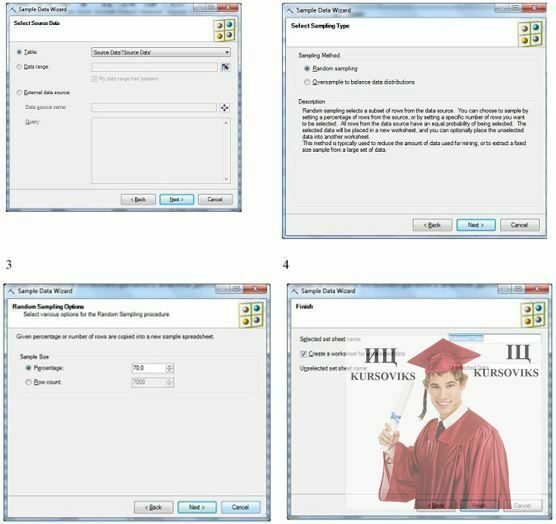
Рис. 6 - Інструмент Sample Data
Запустимо інструмент Sample Data, вкажемо як джерело даних використовувану таблицю Excel і виберемо варіант формування надлишкової вибірки з балансуванням даних (Oversample to balance data distributions, рис. 7-2). Далі вкажемо стовпець, для якого виконується балансування, і частоту появи потрібного значення і розмір вибірки (рис. 7-3). Буде створена нова таблиця з вказаним користувачем назвою. Знову застосуємо Explore Dataі переконаємося в тому, що вибірка сформована відповідно до зазначених вище вимог ( рис. 7-4).

Рис. 7 - Формування вибірки із заданим розподілом клієнтів по регіонах
Завдання. Проведіть описану в лабораторній роботі обробку обраного набору даних.