








Лабораторна робота №2, Виконання аналізу даних методами data mining – Варіант №2
Код роботи: 2496
Вид роботи: Лабораторна робота
Предмет: Інтелектуальний аналіз данних
Тема: №2, Виконання аналізу даних методами data mining – Варіант №2
Кількість сторінок: 22
Дата виконання: 2017
Мова написання: українська
Ціна: 250 грн (+ програма)
Мета: Вивчити основні етапи інтелектуального аналізу даних з використанням алгоритмів data mining реалізованих в бібліотеці Xelopes.
Завдання: Для даних з файлу визначених варіантом завдання побудувати моделі також відповідно до варіанту завдання допомогою різних алгоритмів і пояснити результати.
Загальні відомості
2.1. Введення
Процес інтелектуального аналізу даних складається з наступних основних етапів:
1. Підготовка даних у вигляді зручному для вживання методів data mining
2. Налагодження процесу побудови mining моделі
3. Побудова mining моделі
4. Аналіз побудованої mining моделі
5. У разі supervised моделі вживання її до нових даних
2.2. Підготовка початкових даних
Процес підготовки припускає збір даних для аналізу з різних джерел даних і представлення їх у форматі придатному для вживання алгоритмів data mining.
Справжня версія Xelopes підтримує ARFF (Attribute-Relation File Format) формат представлення даних. Він розроблений для бібліотеки Weka в університеті Waikato. ARFF файл є ASCII текстовим файлом, що описує список об'єктів із загальними атрибутами.
Структурно такий файл розділяється на дві частини: заголовок і дані.
У заголовку описується ім'я даних і їх метадані (імена атрибутів і їх типи). Наприклад,
@relation weather
@attribute outlook {sunny, overcast, rainy}
@attribute temperature real
@attribute humidity real
@attribute windy {true, false}
@attribute whatIdo {will_play, may_play, no_play}
У другій частині представлені самі дані. Наприклад,
@data
overcast,75,55,false,will_play
sunny,85,85,false,will_play
sunny,80,90,true,may_play
overcast,83,86,false,no_play
rainy,70,96,false,will_play
rainy,68,80,false,will_play
rainy,65,70,true,no_play
overcast,64,65,true,may_play
sunny,72,95,false,no_play
sunny,69,70,false,will_play
rainy,75,80,false,will_play
sunny,75,70,true,may_play
overcast,72,90,true,may_play
overcast,81,75,false,will_play
rainy,71,91,true,no_play
2.2.1. Заголовок
Заголовок містить інформацію про ім'я файлу і метадані про представлені в ньому дані. Ім'я описується в наступному форматі
@relation <имя>
Ім'я може бути будь-яка послідовність символів. Якщо ім'я включає пропуски то воно повинне бути укладено в лапки. Наприклад
@relation weather
@relation “weather nominal”
Мета дані описують атрибути представлених у файлі даних. Інформація про кожний атрибут записується в окремому рядку і включає ім'я атрибуту і його тип. Очевидно, що імена повинні бути унікальні. Порядок їх опису повинен співпадати з порядком колонок опису даних. Загальний формат опису атрибуту наступний:
@attribute <имя атрибута> <тип атрибута>
Наприклад,
@attribute outlook {sunny, overcast, rainy}
@attribute temperature real
Ім'я атрибуту повинне починатися з символу. У випадку якщо воно містить пропуски, то повинен бути укладено в лапки.
Значенням поля <тип> може бути одне з наступних п'яти типів:
- real
- integer
- <категория>
- string
- date [<формат даты>]
Типи real і integer є числовими. Категоріальні типи описуються переліком категорій (можливих значень). Наприклад:
@attribute outlook {sunny, overcast, rainy}
При описі дати можна вказати формат в якому вона записуватиметься (наприклад, “yyyy-MM-dd”).
2.2.2. Дані
Дані представляються в ARFF форматі у вигляді списку значень атрибутів об'єктів після тега @data. Кожний рядок списку відповідає одному об'єкту. Кожна колонка відповідає атрибуту описаному в частині заголовка. Причому порядок проходження колонок повинен співпадати з порядком опису атрибутів. Наприклад:
@data
overcast,75,55,false,will_play
sunny,85,85,false,will_play
sunny,80,90,true,may_play
Часто в термінології data mining такі рядки називають векторами.
Дані можуть містити пропущені (невідомі) значення. В ARFF вони представляються символом «?», наприклад:
@data
4.4,?,1.5,?,Iris-setosa
Рядкові дані у випадку якщо вони містять розділяючі слова символи, повинні полягати в лапки. Наприклад,
@relation LCCvsLCSH
@attribute LCC string
@attribute LCSH string
@data
AG5, 'Encyclopedias and dictionaries.;Twentieth сеntury.'
AS262, 'Science -- Soviet Union -- History.'
AE5, 'Encyclopedias and dictionaries.'
AS281, 'Astronomy, Assyro-Babylonian.;Moon -- Phases.'
AS281, 'Astronomy, Assyro-Babylonian.;Moon -- Tables.'
Дати також повинні бути укладені в лапки. Якщо при описі відповідного атрибуту б вказаний формат дати, то дані повинні бути записані відповідно до нього:
@relation Timestamps
@attribute timestamp DATE "yyyy-MM-dd HH:mm:ss"
@data
"2001-04-03 12:12:12"
"2001-05-03 12:59:55"
2.3. Налагодження процесу побудови mining моделі
Результатом аналізу даних за допомогою методів data mining є структури нові знання, що є. Такі структури називаються моделями. Вони можуть бути різних видів: правила класифікації, асоціативні правила, дерева рішень, математичні залежності і т.п. Вид моделі багато в чому залежить від методу за допомогою якого вона була побудована. Таким чином, кінцевий результат залежить від методу і початкових даних. Крім того, процес побудови моделей можна набудувати змінюючи тим самим властивості моделі (точність, глибина дерева і т.п.). Параметри, що настроюються, залежать від конкретної моделі.
У GUI Xelopes користувач має нагоду виконати налагодження для кожної моделі, що будується, індивідуально. Цей процес здійснюється в діалоговому вікні налагодження, описаному в попередній лабораторній роботі на закладці Settings. Далі розглянемо детальніше налагодження для кожної моделі.
2.3.1. Налагодження для асоціативних правил і сиквенциального аналізу
Налагодження для моделі представляючої асоціативні правила виконуються в діалоговому вікні зображеному на рис. 1.
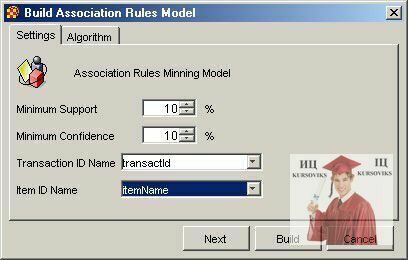
Рис. 1 - Налагодження моделі асоціативних правил
У ньому виконується налагодження наступних параметрів:
- Minimum Support – мінімальне значення підтримки для шуканих частих наборів і асоціативних правил, що будуються. Значення повинне бути більше нуля, інакше не буде побудовано не одного правила.
- Minimum Confidence – мінімальне значення довір'я для асоціативних правил, що будуються. Значення повинне бути більше нуля, інакше не буде побудовано не одного правила.
- Transaction ID Name – атрибут унікально ідентифікуючий транзакції (ключове поле).
- Item ID Name – атрибут що є іменами об'єктів. Вони використовуються для побудови правил. Від його вибору залежить ступінь розуміння одержаних результатів.
Налагодження для сіквенціальної моделі виконуються в діалоговому вікні зображеному на рис. 2.
Рис. 2 - Налагодження сіквенціальної моделі
У ньому виконується налагодження аналогічні моделі асоціативних правил. Додатково з'являється параметр Item transaction position, щопредставляє атрибут, що ідентифікує позицію елементу в послідовності.
2.3.2. Налагодження для дерев рішень (Decision Tree Mining Model)
Налагодження для моделі представляючої дерева рішень виконуються в діалоговому вікні зображеному на рис. 3.
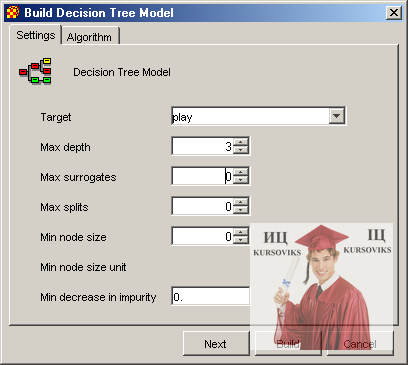
Рис. 3 - Налагодження моделі дерев рішень
У ньому виконується налагодження наступних параметрів:
- Target – атрибут по якому виконується класифікація даних (незалежна змінна).
- Max depth – максимально допустима глибина дерева, що будується
- Max surrogates - максимально допустиме число замін
- Max splits - максимально допустима кількість розщеплювань
- Min node size – мінімальний розмір вузла дерева
- Min decrease in impurity – мінімальний ступінь домішок
2.3.3. Налагодження для математичної залежності побудованої методом SVM
Налагодження для моделі представляючу математичну залежність, побудовану методом SVM, виконуються в діалоговому вікні зображеному на рис. 4.
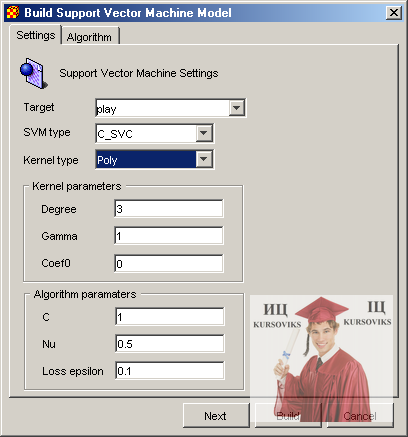
Рис. 4 - Налагодження моделі SVM
У ньому виконується налагодження наступних параметрів:
- Target – атрибут по якому виконується класифікація даних (незалежна змінна).
- SVM Type – тип моделі SVM. В Xelopes можуть бути побудовані наступні типи: C-SVC (classical SVM), Nu-SVC, one-class SCM, Epsilon-SVR (classic regression SVM), Nu-SVR. Вони відрізняються классифікационнй функції. Так найбільш распростроненная SVM для задачі регресії Epsilon-SVR має функцію вигляду:
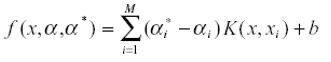
тоді як SVM для класифікації має вигляд
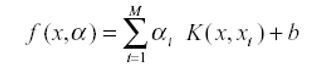
KernelType – вид функції K(x, xi) в класифікаційній функції (тип ядра). Може приймати наступні значення::
Linear - Лінійна - k(x,y) = x*y
Poly - Поліноміал ступені d - k(x,y) =(γ*x*y+с0)d
RBF- Базова радіальна функція Гауса- k(x,y) =exp(-γ||x – y||)
Sigmoid - Сигмоїдальна k(x,y) = tanh(γ*x*y+с0)
Kernel Parameters – параметры ядра, залежить від обраного типу ядра.
Degree – степень d в ядре poly;
Gamma – параметр γ в последних трех видах;
Coef0 – коэффициент с0 в типах poly и sigmoid.
Algorithm Parameters – общие параметры алгоритмов класса SVM:
С – інверсний регулюючий параметр 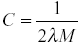 ;
;
Nu – параметр v в типі Nu – SVM;
Loss epsilon – ε функція втрат в типі Epsilon-SVR.
2.3.4. Налагодження кластерної моделі
Налагодження для кластерних центрованою і ієрархічних моделей виконуються в діалоговому вікні зображеному на рис. 5.
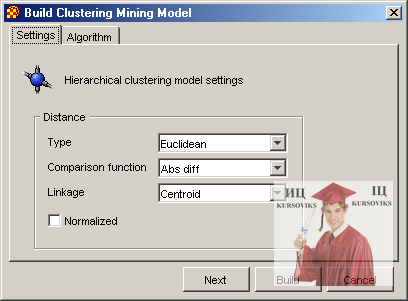
Рис. 5 - Налагодження для кластерної моделі
У ньому виконується налагодження наступних параметрів:
- Maximum number clusters – максимальна кількість побудованих кластерів. Знченіє параметра повинне бути більше нуля.
- Distance – параметри характеризуючі функцію обчислення відстані між об'єктами:
- Type – тип функції відстані. Xelopes (Евклідово – Euclidean, Чебишева – Chebyshev і ін.)
- Comparison function – функція зіставлення.
- Normalized – чи використовувати нормалізацію при розрахунку відстаней.
Налагодження для кластерної моделі, що розділяється, виконуються в діалоговому вікні зображеному на рис. 6.
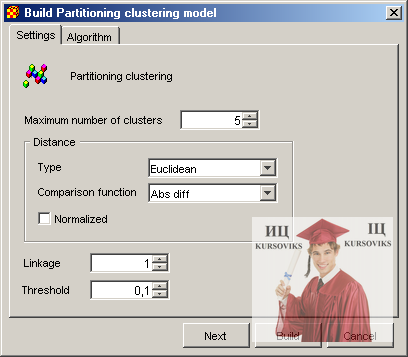
Рис. 6 - Налагодження для кластерної моделі, що розділяється
У ньому виконується налагодження додаткових параметрів параметрів:
- Linkage – параметр до для алгоритму к-linkage.
- Threshold – межа для відстані.
2.4. Анализ моделей
Для вживання одержаних за допомогою методів data mining знань необхідно проаналізувати побудовані моделі. При аналізі необхідно перевірити наскільки одержані знання є логічно з'ясовними, чи не суперечать вони здоровому глузду, чи дійсно вони є новими і т.п. Крім того, моделі, що будуються при рішенні задач асоціативного аналізу і кластеризації, є описовими, тобто служать для кращого розуміння самих даних. У зв'язку з цим можна зробити висновок, що важливим є представлення моделей у вигляді зручному для їх аналізу людиною.
У GUI Xelopes будь-яка модель може бути представлена у форматі PMML. Це стандартизованих формат заснований на форматі XML. На жаль для візуального аналізу даний формат досить складний. З цієї причини в GUI Xelopes реалізовані спеціальні засоби візуалізації для трьох основних видів моделей:
- асоціативні правила;
- дерева рішень;
- дейтограмми.
2.4.1 Візуалізація асоціативних правил
Модель представляюча асоціативні правила в GUI Xelopes представляється у вигляді 3-х мірних гістограм (рис. 7). По осях площини відкладаються підмножини частих наборів. LHS – означає ліву частину правил, RHS – праву. На їх перетині малюється гістограма. За умовчанням висота гістограма відображає рівень підтримки правила включаючого в умовну і завершальну частини дані набори. Колір від синього до червоного (від меншого до більшого) рівень довір'я.
Наприклад, для правила Якщо (Nut) то (Соку) намальована червона висока гістограма означає що дане правило має найбільший ступінь підтримки з високим ступенем довір'я. Правило Якщо (Water) то (Cracker, Соку) має низький рівень підтримки і низький ступінь довір'я.
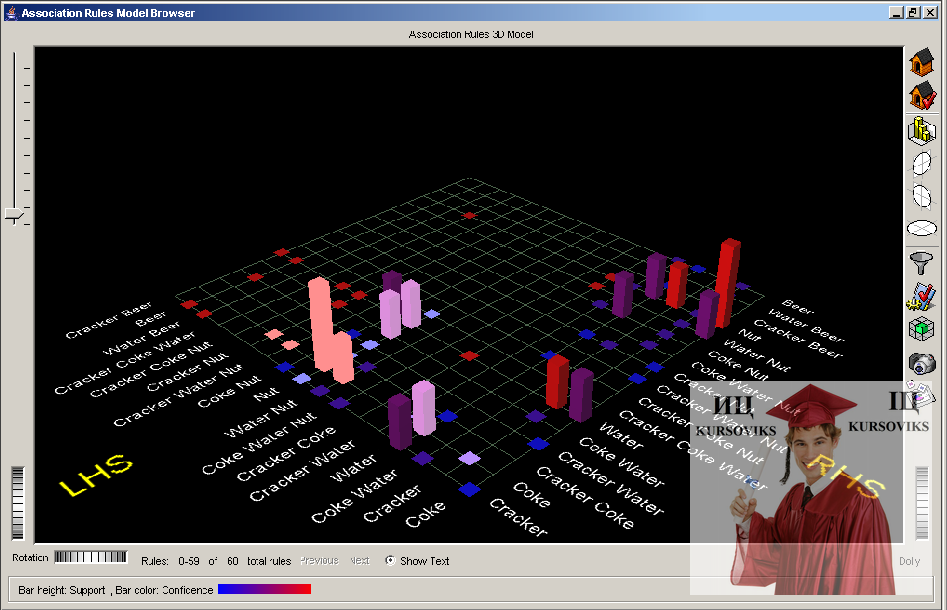
Рис. 7 - Візуальне представлення асоціативних правил
Для детальнішого вивчення правил необхідно виділити гістограму на перетині наборів, що цікавлять. Візуально вони підсвічуються яскравішим кольором. На рис. Виділена гістограма Nut – Соke. Для виділених наборів можна детальніше подивитися гістограми їх оцінок. Для цього необхідно на панелі інструментів зліва від діаграма натискувати кнопку  . У результаті з'явиться діалог зображений на рис. 8.
. У результаті з'явиться діалог зображений на рис. 8.
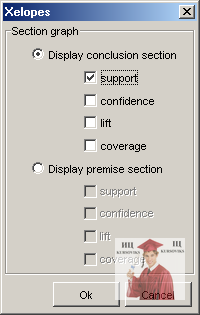
Рис. 8 - Діалог для деталізації оцінок асоціативних правил
У ньому можна вибрати які оцінки повинні деталізуватися. Після натиснення на кнопку ОК, з'являться діаграми (Рис. 9) оцінок для виділених наборів.
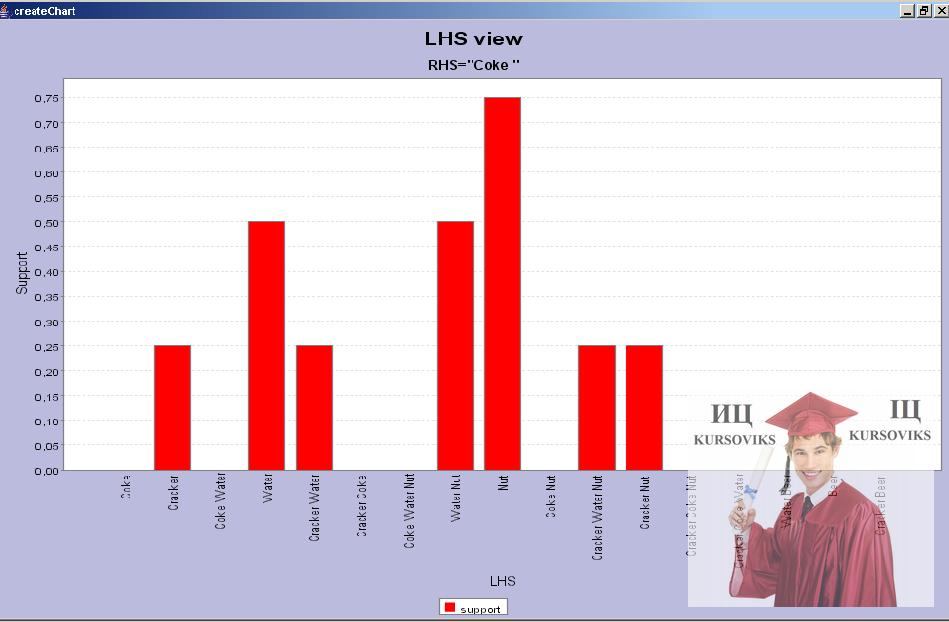
Рис. 9 - Приклад діаграми підтримки
2.4.2. Візуалізація дерев рішень
Модель представляюча дерева рішень в GUI Xelopes представляється в дерева (рис. 10). Вузлами дерева є вирази визначальне розбиття безлічі об'єктів на підмножини. Нижня частина в кожному вузлі відображає рівень входження в множину відповідну вузлу об'єктів відносяться до різних класів. Можна помітити, що листя дерева відповідні підмножинам містять об'єкти одного класу мають одноколірну нижню частину. Підписи на гілках дерева відображають умови переходу по цій гілці.
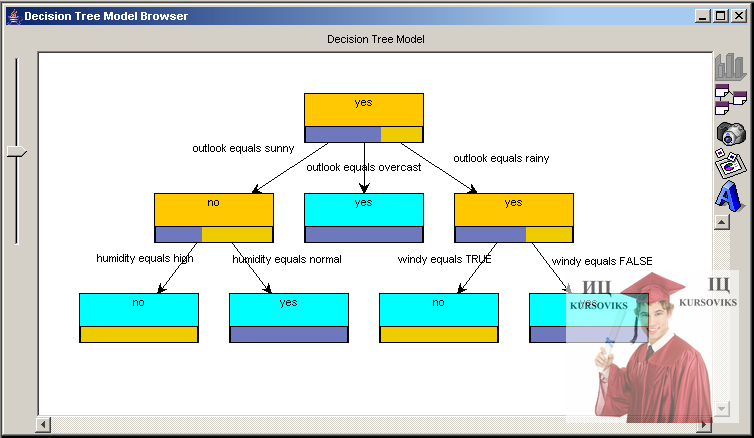
Рис. 10 - Приклад візуалізації моделі дерева рішень
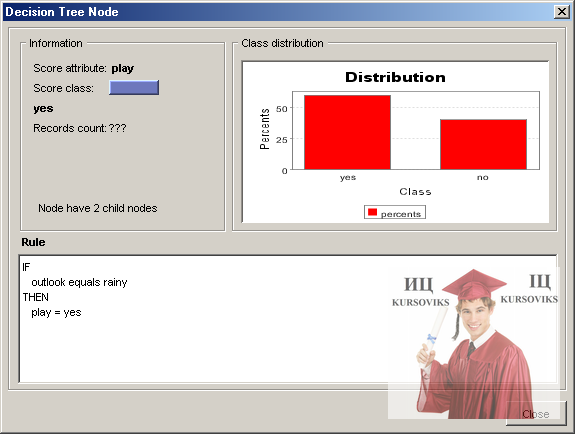
Рис. 11 - Приклад візуалізації моделі дерева рішень
По кожному вузлу дерева можна одержати додаткову інформацію. Для цього необхідно виділити вузол і або вибравши в контекстному меню пункт Node Information або натискувати на кнопку Node Info на панелі інструментів зліва від діаграми. В результаті з'явиться вікно (рис. 11) представляючу наступну інформацію про вузол:
- Information – інформація про вузол:
- Score attribute – порівнюваний атрибут (залежна змінна)
- Score class – значення з яким виконується порівняння
- Records count – кількість об'єктів покритих вузлом
- Кількість гілок виходять з вузла.
- Class distribution – розподіл об'єктів відносяться до різних класів для даного вузла
- Rule – класифікаційне правило відповідне даному вузлу.
2.4.3. Візуалізація ієрархічної кластеризації
Модель представляюча ієрархічну кластеризацію рішень в GUI Xelopes представляється у вигляді дейтограми (рис. 12). Верхній вузол є кластером відповідним всій безлічі об'єктів. Листя відповідає кластерам містять по одному елементу з початкової множини.
За допомогою миші можна задати рівень кластеризації. На дейтаграмі він представляється у вигляді лінії. При цьому виводитиметься інформація про середню відстань між кластерами. Об'єднувані кластери при заданому рівні виділяються червоним кольором.
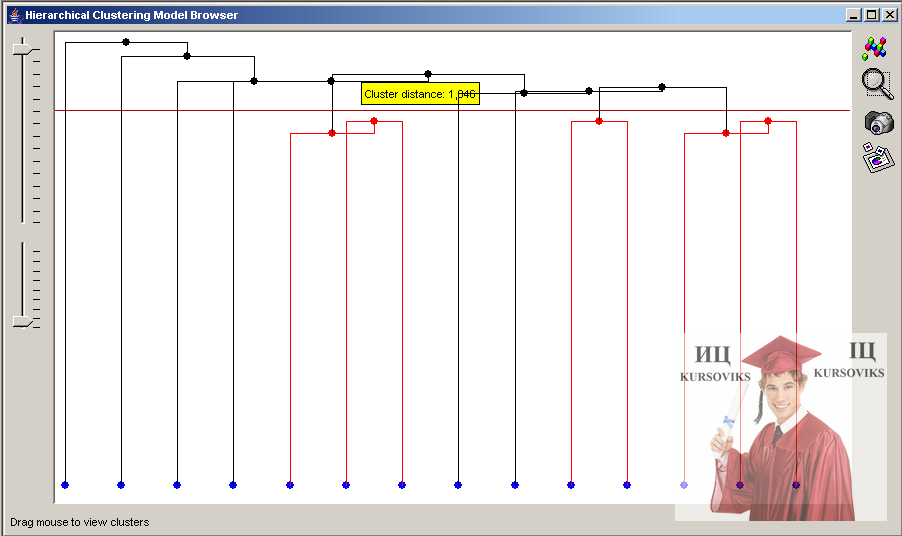
Рис. 12 - Приклад візуалізації дейтограмми
По кластеризації можна одержати детальнішу інформацію, натискуючи на кнопку  на панелі інструментів зліва від діаграми. В результаті з'явиться вікно представлене на рис. 13.
на панелі інструментів зліва від діаграми. В результаті з'явиться вікно представлене на рис. 13.

Рис. 13 - Інформація, що деталізується, про кластери
У вікні в табличному вигляді відображається інформація про кластери для заданого рівня. Над таблицею відображається інформація про кількість кластерів. Колонки в таблиці містять наступну інформацію:
- N – номер кластерів
- Distance – відстань між кластерами.
- Weight – вага кластера (в даному випадку кількість об'єктів потрапили в кластер)
- Number vectors - кількість об'єктів потрапили в кластер.
Натискуючи на кнопку View vectors можна проглянути інформацію про початкові дані.
Порядок виконання роботи
1. Підготувати нові дані у форматі ARFF ту ж структуру, що має, що і дані у файлі заданому варіантом завдання без значень незалежної змінної.
2. Відкрити GUI інтерфейс бібліотеки Xelopes.
3. Завантажити початкові дані з файлу вказаного у варіанті завдання.
4. Проглянути завантажені дані.
5. Проглянути інформацію про атрибути даних.
6. Проглянути статистичну інформацію про дані.
7. По черзі спробувати побудувати моделі певні варіантом завдання кожним з доступних алгоритмів для різних параметрів налагодження.
8. Візуалізувати і порівняти моделі, побудовані різними алгоритмами.
9. Переглянути і зберегти побудовані моделі у форматі PMML.
10. Застосувати моделі типу supervised до даних, підготовлених на кроці 1.
Варіанти завдання
|
Варіант |
Файл |
Моделі |
|
|
1 |
contact-lenses.arff |
Sequential Mining Model, Decision Tree Mining Model, Hierarchical Clustering Mining Model |
|
|
2 |
weather.arff |
Customer Sequential Mining Model Support Vector Machine Mining Model, CDBased Clustering Mining Model |
|
|
3 |
weather-nominal.arff |
Association Rules Mining Model Decision Tree Mining Model Hierarchical Clustering Mining Model |
|
|
4 |
iris.arff |
Association Rules Mining Model Support Vector Machine Mining Model Partition Clustering Mining Model |
|
|
5 |
iris-transact.arff |
Customer Sequential Mining Model, Support Vector Machine Mining Model, Hierarchical Clustering Mining Model |
|
|
6 |
iris-nontransact.arff |
Association Rules Mining Model Decision Tree Mining Model Partition Clustering Mining Model |
|
|
7 |
transact.arff |
Association Rules Mining Model, Support Vector Machine Mining Model CDBased Clustering Mining Model |
|
|
8 |
custom-transact.arff |
Association Rules Mining Model Decision Tree Mining Model CDBased Clustering Mining Model |
|
Звіт по роботі
1. Титульний лист.
2. Мета роботи.
3. Дані з файлу певного варіантом завдання і інформація про них.
4. Список моделей, які не вдалося побудувати для даних з поясненнями чому.
5. Для кожної моделі список алгоритмів, які не побудували модель для даних з поясненнями чому.
6. Кожну модель, побудовану різними алгоритмами з описом відмінностей між ними і поясненнями.
7. Моделі, побудовані одним алгоритмом при різних параметрах налагодження з описом відмінностей і поясненнями.
8. Результат вживання моделі типу supervised до нових даних.
9. Висновки по роботі.
Контрольні питання
1. Які проблеми виникають з початковими даними.
2. Чому для одних і тих же даних не можуть бути побудовані всі види моделей.
3. Які вимоги на початкові дані накладають різні алгоритми data mining.
4. Які параметри необхідно набудувати для побудови асоціативних правил. Як від них залежить результат (побудована модель).
5. Які параметри необхідно набудувати для побудови дерева рішень. Як від них залежить результат (побудована модель).
6. Які параметри необхідно набудувати для виконання кластеризації. Як від них залежить результат (побудована модель).
7. Які параметри визначаються алгоритмами. Привести приклади. Як від них залежить результат (побудована модель).
8. Що таке сиквенціальний аналіз і ніж він відрізняється від пошуку асоціативних правил.