








Лабораторна робота №5, Скорингові моделі. Логістична регресія
Код роботи: 872
Вид роботи: Лабораторна робота
Предмет: Системи підтримки та прийняття рішень (СППР)
Тема: №5, Скорингові моделі. Логістична регресія
Кількість сторінок: 1
Дата виконання: 2015
Мова написання: українська
Ціна: 250 грн
Теоретичні відомості
В даній лабораторній роботі ми розглянемо, як алгоритм Data Mining використовувати для побудови скоригованих моделей в банківській діяльності.
Аналітичні алгоритми мають дуже широке коло застосувань в банках: від консолідації та візуалізації даних до моделювання та управління ризиками.
Кредитному скорингу приділяється особлива увага, оскільки він є ключовим в процесі прийняття рішення щодо видачі кредиту (рис. 1).

Рис. 1. Схема бізнес-процесу видачі кредиту
Отже, кредитний скоринг – це метод, що використовує математичні або статистичні моделі, які на основі кредитних історій «минулих» клієнтів банків намагаються передбачити повернення (або неповернення) кредиту новим клієнтам.
Кредитний скоринг передбачає побудову математичної моделі (скорингової моделі), на вхід якої подаються певні характеристики клієнта (вік, дохід, стаж роботи і т. д.), а на виході формується інтегрований показник («score» - бал), який визначає ймовірність повернення або неповернення кредиту. На основі цієї ймовірності приймається рішення про видачу / невидачу кредиту.
Відмітимо, що побудова скорингових моделей є дуже актуальною нині задачею.
В більшості вітчизняних банків визначення кредитного рейтингу клієнта визначається експертним методом (тобто людиною), що завжди має високий ступінь суб’єктивності. Звичайно, при цьому «експерти» використовують певні правила та показники, яким повинні відповідати параметри кредитоотримувача і які в деякій мірі мінімізують людський фактор та помилку, але повністю позбутися цієї проблеми дуже тяжко.
Криза 2008 – 2009 в банківському секторі, крім масового відтоку депозитів, запам’яталася значним ростом на балансах банків так званих «токсичних» та проблемних активів (тобто кредитів). В першому випадку («токсичні») – кредити з затриманими платежами і фактично без шансів на повернення, тобто їх потрібно списувати, а в другому (проблемні) – це кредити, які виплачуються із затримкою. Навіть активне застосування колекторських механізмів не дало бажаного позитивного результату і дана ситуація обернулася для банків суттєвими збитками. Однією з причин такої ситуації була відсутність належного контролю банків за прийняттям рішення щодо видачі кредиту. Цю ситуацію також активно стимулювали дешеві внутрішні та зовнішні кредитні ресурси, які могли залучити банки. Часто рішення про видачу кредиту приймали молоді спеціалісти, які не мали відповідного досвіду для оцінки параметрів клієнта.
Автоматизована скорингова система дозволила б уникнути багатьох помилок.
Наслідки тієї ситуації, що описана вище, є те, що банки суттєво підвищують вимоги до бажаючих взяти кредит. Внаслідок цього видавати кредити стає просто нікому. Виникає питання, а чи не надто сильно «закручені гайки?» Чи адекватно проаналізовано минулі випадки з неповерненням? І тут скорингова система може дати чітку відповідь.
Ще один випадок, коли використання автоматизованих скорингових систем є вкрай важливим. Це споживчі кредити в торгових точках.
Кожен з Вас бачив, що в маркетах (Фокстрот, Фоксмарт, Комфі, Епіцентр) чи великих магазинах (КТС) видаються швидкі споживчі кредити для купівлі техніки тощо. В таких випадках вкрай важливим фактором є час видачі кредиту. Розглядати кредитну заявку день чи два є неприйнятним – гроші потрібні тут і зараз. Тому бізнес-процес на рис. 1 потрібно скоротити, при цому ключовим стане саме автоматизований скоринг.
За оцінками аналітиків компанії BaseGroup повна автоматизація бізнес-процесу видачі кредиту (рис. 1) дозволить скоротити час розгляду заявки в 20 разів.
Скорингові моделі – це загальний інструмент.
Їх потрібно реалізовувати за допомогою конкретних алгоритмів.
Найпростіший – це побудувати скорингову таблицю, що часто роблять експерти, але більш ефективним вважається використання самонавчальних алгоритмів, що мають здатність до адаптації, тобто автоматичного врахування нових даних, і перелаштуванню параметрів моделі.
Для цієї мети використовують:
1. Логістичну регресію.
2. Дерева рішень.
3. Нейронні мережі.
Кожен з цих алгоритмів має свої помилки та мінуси. Загальне правило таке: чим точніші результати алгоритму, тим складніше сам алгоритм і інтерпретація його результатів.
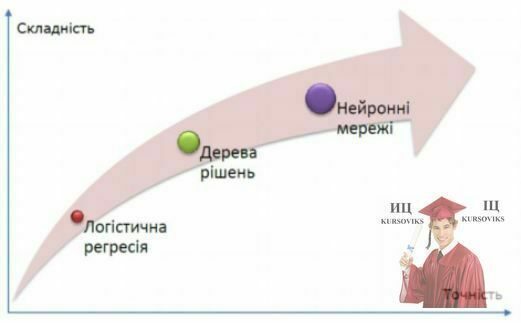
Рис. 2. Взаємозв’язок між складністю та точністю алгоритмів скорингу
Практичне завдання
Вхідні дані
Вхідний набір даних містить 13 полів, які описані в таблиці 1. Відмітимо, що вхідні дані, як правило, беруться з інформаційної системи банку, яка містить всю інформацію по кредитних договорах.
Таблиця 1
Характеристика полів вхідного набору даних

Зробимо кілька важливих зауважень:
1. При побудові скорингових моделей часто неперервні числові значення замінюють на категорійні. Наприклад, «Стажробои» можна бло б деталізувати і залишити значення, скажімо: 0,5; 1; 2; 3 і т. д. Але вважається, що заміна на інтервали (категорії) «Менше 1 року, від 1 до 3 років, більше 3 років» дозволяє легше інтерпретувати результати моделі, хоча ймовірна невелика втрата якості. Відмітимо, що переведення неперервних числових (1; 2; 3; 5 і т. д.) в категорійні інтервальні значення здійснюється в DEDUCTOR'і через обробник «Квентование».
2. Часто замість поля «Дохід» використовують полі «Зобов’язання / Дохід» або «Платіж / Дохід». Чому так роблять? Скажімо, клієнт має місячний дохід 5000 грн. це достатньо чи мало для виплати кредиту? Якщо він бере кредит 10000 грн. з місячним платежем 1000 грн., то очевидно, що дохід дозволяє виплачувати кредит. Якщо ж береться кредит на млн. грн., то дохід недостатній для обслуговування кредиту. Крім того, для першого випадку дохід також може бути недостатній, якщо клієнт вже має кредит із щомісячним платежем в 3000 грн.
Вважається, що дані показники повинні задовольняти умови: П/Д < 40%,З /Д < 50-60%. Більш легше отримати показник П/Д. оскільки у варіанті використання З/Д чисельник («зобов’язання») повинні включати виплати по іншим кредитам, аліменти, витрати на утримання сім‘ї тощо, що визначити значно складніше.
Для отримання коректних результатів скориговану модель спочатку будують на навчальній вібрації, а пізніше перевіряють на тестовій. Тому виникає питання, як поділити всю вхідну вибірку на вказані дві множини. Це можна зробити автоматично в самому DEDUCTOR'і на основі випадкового розбиття. Але тут може виникнути проблема. Припустимо, що в нас є дані про виконання кредитних договорів по 20 клієнтах (16 позитивних випадків та 4 негативних випадки виплат по кредиту).
Ми на основі випадкового алгоритму розбиваємо цю вибірку на навчальну і тестову у співвідношенні 80% на 20 % відповідно. Тоді чисто теоретично може виникнути ситуація, коли DEDUCTOR всі 16 позитивних випадків помістить у навчальну вибірку, а 4 – в тестову. Після цього наша скоригована модель не зможе прогнозувати невиплати по кредиту, оскільки вона «не знає», що такі невиплати взагалі можуть існувати, оскільки вчилася тільки на «хороших» прикладах.
Тому часто у вхідній вибірці кожному рядку вказують до якої вибірки він відноситься, щоб забезпечити рівномірне представлення у навчальній та тестові вибірці «хороших» та «поганих» клієнтів.
Таким чином, в нашій задачі представлено 2209 кредитів (файл «data _ scoring.txt) з відомими платежами протягом декількох місяців після видачі кредиту. Набір даних вже розбитий на дві множини – навчальну (80%) і тестову (20%) – за допомогою процедури так званого стратифікованого семплінгу так, щоб у кожній множині частка «поганих» кредитів була приблизно однаковою.
Створення додаткового поля «Репутація клієнта» (виконайте в DEDUCTOR'і)
Для зручності на основі поля «Затримка більше 60 днів» створіть нове поле «Репутація клієнта» на основі такого правила: якщо «Затримка більше 60 днів» = 1, то «Репутація клієнта» = «Поганий», а якщо «Затримка більше 60 днів» = 0, то «Репутація клієнта» = «Хороший».
Саме поле «Репутація клієнта» буде далі вихідним полем при побудові всіх скорингових моделей.
Скорингові моделі на основі логістичної регресії
Логістична регресія – це різновид множинної регресії, яка, як відомо, аналізує зв'язок між кількома незалежними змінними (хі) і залежно змінної (у). Бінарна логістична регресія, яка випливає з назви, застосовується у випадку, коли залежна змінна є бінарною (тобто може приймати лише два значення). Іншими словами, за допомогою логістичної регресії можна оцінювати ймовірність того, що подія наступить для конкретного випадку (хворий / здоровий / повернення кредиту / дефолт і т. д.).
Модель логістичної регресії, як різновид множинної, має вигляд:
![]()
Однак тут є складність. Модель (1) «не знає», що вихідна зміна у повинна бути бінарною, тобто приймати лише два значення, наприклад, 1 (давати кредит) або 0 (не давати кредит). Ця проблема вирішується в два кроки:
1. За допомогою так званого логіт – перетворення  модель має на виході ймовірність повернення кредиту, що знаходиться в діапазоні (0,1).
модель має на виході ймовірність повернення кредиту, що знаходиться в діапазоні (0,1).
2. Вибирається певне число b – поріг (точка) відсікання, що відносить подію до однієї з двох бінарних подій (давати / не давати кредит). Наприклад, логіт – перетворення дало значення Р= 0,75 – це означає, що з ймовірністю 75 % клієнт буде вчасно виплачувати кредит. Якщо вибрати b = 0,8, то клієнт буде віднесений до неблагонадійних і кредит виданий не буде (оскільки Р = 0,75 < b = 0,8). Число b має дуже велике значення для результатів скоригованої моделі на основі логістичної регресії.
Перейдемо до практичної побудови в DEDUCTOR'і скоригованої моделі на основі логістичної регресії.
Побудова автоматизованої скоригованої системи на основі логістичної регресії (виконайте в DEDUCTOR'і)
1. Для побудови логістичної регресії запустіть однойменний розробник.
2. На 2 кроці вкажіть призначення полів:
А) «Код» і «Дата» - інформаційні (оскільки не несуть жодного смислового навантаження)
Б) «Тестова множина» - інформаційне (це службове слово, що вказує на розподіл навчальної і тестової вибірки).
С) «Затримка більше 60 днів» - не використовуємо (оскільки на основі цього поля створено нове, яке і буде приймати участь в моделі)
Д) «Репутація клієнта» - вихідне поле.
Е) Всі інші поля – вхідні.
В цьому ж вікні (крок 2) зверніть увагу на кнопку «Настройка нормализации). Справа в тому, що всі поля, як подаються на вхід логістичної регресії повинні мати числовий тип, хоча насправді у вхідних даних (табл. 1) багато стрічкових (категорійних) значень. Виходом з цієї ситуації є числове кодування полів, що робиться DEDUCTOR'ом автоматично саме у вікні «Настройка нормализации».
В даному випадку виділіть поля від «Проживання» «Кредитної історії» і задайте їм «Способ кодирования» - «Комбинация битов».

Рис. 3. Deductor - «Способ кодирования» - «Комбинация битов»
Також дуже важливим є те, який порядок сортування унікальних значень вихідного поля «Репутація клієнта». Першим в таблиці повинен бути негативний результат («Поганий»), а другим – позитивний результат («Хороший»).
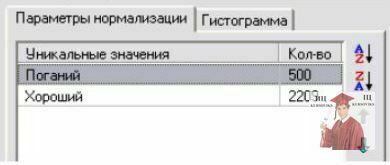
Рис. 4. Deductor – результат таблиці
Якщо зробити навпаки, то логістична регресія буде давати невірний результат: хороший клієнт стане поганим і навпаки – поганий стане хорошим.
3. На кроці 3 потрібно вказати, що розподіл на навчальну і тестову вибірки буде здійснюватися по стовпцю «Тестова множина». Але при спробі це зробити, скоріш за все, у Вас виникне помилка:
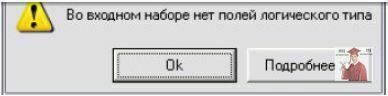
Рис. 5. Висновок по логістичному типу в Deductor
Прочитайте зміст помилки та виправте її.
В результаті на 3 кроці вікно має виглядати наступним чином:

Рис. 6. Розділення початкової множини даних Deductor
4. На 4 кроці поки-що все залишаємо без змін, але зверніть увагу на поле «Порог отсечения»

Рис. 7. Deductor - Порог отсечения
В цьому полі задається значення важливого числа b, про яке говорилося вище,. До нього ми ще повернемося.
5. На 5 кроці виконуємо побудову логістичної регресії через кнопку «Пуск».
6. На 6 виводимо наступні візуалізатори:
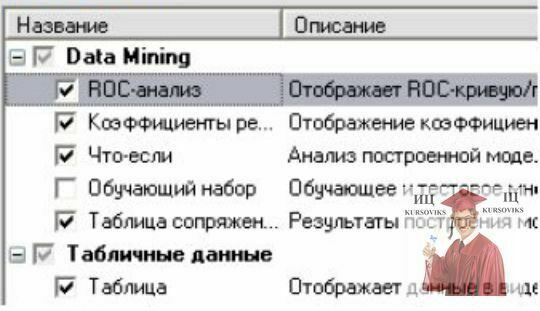
Рис. 8. Візуалізатори в Deductor
Аналіз отриманих результатів логістичної регресії
Проаналізуємо результати кожного візуалізатора:
1. «Таблица» - фактично це є вхідна таблиця даних, але в ній з’явилося два нових поля:
a. «Репутація клієнта Рейтинг» - це ймовірність повернення кредиту клієнтом.
b. «Репутація клієнта OUТ» - це «вирок» клієнту: хороший чи поганий на основі порівняння значення попереднього поля з точкою відсікання (в даному випадку ми залишили по замовчуванню b = 0,5)
Пізніше ці два нових поля можна оброблювати в інших обробниках чи візуалізаторах. Так, наприклад, на основі візуалізатора статистика більшості кредит беруть звичайні працівники і т. д.
2. «Что - если» - візуалізатор дозволяє інтерактивно визначити репутацію клієнта на основі довільних його характеристик. Крім того, через кнопку  можна вивести графік, який показує залежність кредитного рейтингу від вхідних параметрів. Так, якщо через кнопку
можна вивести графік, який показує залежність кредитного рейтингу від вхідних параметрів. Так, якщо через кнопку  вибрати «З/Д, %», а кнопкою
вибрати «З/Д, %», а кнопкою  - «Репутація клієнта Рейтинг», то ми зможемо побачити на графіку, що із зростанням рівня зобов’язань кредитний рейтинг падає. Аналогічно можна подивитися, що із зростанням віку клієнтів їх кредитний рейтинг росте.
- «Репутація клієнта Рейтинг», то ми зможемо побачити на графіку, що із зростанням рівня зобов’язань кредитний рейтинг падає. Аналогічно можна подивитися, що із зростанням віку клієнтів їх кредитний рейтинг росте.

Рис. 9. Deductor - Репутація клієнта Рейтинг
3. «Коэффициенты регрессии» - на цьому візуалізаторі ми можемо оцінити дві речі:
а. «Коэффициенты» - це коефіцієнти рівняння логістичної регресії (1), тобто а0, а1 … аn. Єдине, на що звернемо увагу, це збільшення вхідних змінних моделі. Так, раніше в нас була одна змінна «Освіта», а внаслідок кодування стало три: «Освіта середня» 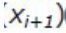 , «Освіта середня спеціальна»
, «Освіта середня спеціальна»  та «Освіта вища»
та «Освіта вища» 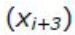 . Наприклад, якщо клієнт має вищу освіту, то ці вказані змінні («ікси») набудуть значень:
. Наприклад, якщо клієнт має вищу освіту, то ці вказані змінні («ікси») набудуть значень:
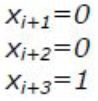
Ці значення підставляються в рівняння (1) з уже відомими коефіцієнтами а0, а1 … аn.
b. «Отношения шансов» - показує наскільки конкретне значення тієї чи іншої характеристики клієнта (наприклад, освіти) дає більше шансів стати «хорошим» клієнтом. Так, розглянемо шанси сімейного стану:

Рис. 10. Отношения шансов - Deductor
Одружений клієнт має шанси стати благонадійним позичальником майже в два рази більше (1,486 / 0Ю796 – 1, 86), ніж неодружений клієнт і в 1,25 рази більше, ніж розлучений чи вдівець (1,486 / 1.183 = 1,25). Якщо подивитися на шанси змінної «З/Д %», то можна сказати, що значення менше одиниці (0,96) показує погіршення репутації клієнта при зростанні кредитних зобов’язань.
4. «Таблица сопряженности» - спеціалізований візуалізатор, який ще називають «матрицею класифікації» показує скільки помилок допустила наша модель. Помилки класифікації бувають двох видів:
А. Помилки першого роду – хороші клієнти розпізнані як погані.
Б. Помилка другого роду – погані клієнти визнані хорошими.
І тут виникає питання, а які помилки більш критичні? Що критичніше для банку: не видати кредит насправді хорошому клієнту, і не отримати відсотки чи видати кредит насправді поганому клієнту, який потім не виплатить ні відсотків, ні «тіло» кредиту? Очевидно, що другий випадок більш збитковий, оскільки втратимо і відсотки, і «тіло» кредиту. Тому потрібно, щоб модель давала якомога менше помилок другого роду. Хоча, для справедливості, потрібно сказати, що на вибір даної стратегії суттєвий вплив має політика банку щодо ризику.
Взагалі на основі «Таблицы сопряженности» можна визначити деякі показники якості моделі.
Приймемо наступні позначення:
- Якщо справді хороший клієнт розпізнаний як хороший – це істинно позитивний результат (true positive, TP)
- Якщо справді хороший клієнт розпізнаний як поганий – це хибно негативний результат (true negative, FN)
- Якщо справді поганий клієнт розпізнаваний як хороший – це хибно позитивний результат (false positive, FP)
Таким чином наша таблиця в умовних позначеннях виглядатиме так:

Рис. 11. Кінцева таблиця Deductor
На основі цього можна визначити кілька показників ефективності моделі:
- Загальний показник успіху або точність моделі – це відношення правильно класифікованих об’єктів до кількості всіх спостережень:
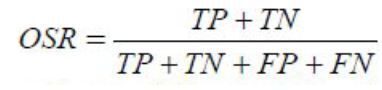
Загальний показник помилки:
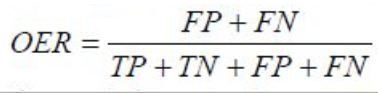
Чутливість – відношення числа істинно позитивних спостережень до числа фактично позитивних спостережень:
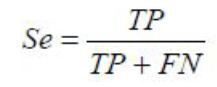
Специфічність – відношення числа істинно негативних спостережень до числа фактично негативних спостережень
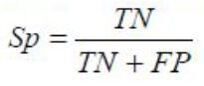
Для будь-яких скорингових моделей (як на основі регресії, так і дерев рішень чи нейромереж) можна визначити дані показники, порівнювати їх і на основі цього визначати оптимальну модель. Дані показники можна порахувати і в Excel і в Deductor.
Так, для побудованої скорингової моделі (на основі логістичної регресії, з коефіцієнтом відсікання = 0,5) показники ефективності моделі наступні (аналогічно побудуйте і ви)

Рис. 12. Розпізнано моделлю Deductor
5. «ROC – кривая» - візуалізатор, який дозволяє оптимізувати результати моделі відповідно до наших цілей (видавати більше кредитів чи більше відсікати потенційно дефолтних позичальників). Щоб не вдаватися в математичні подробиці відмітимо кілька ключових речей цього візуалізатора:
А. Діагональна (зелена) лінія показує рівень безкорисності моделі.
Б. ROC – крива (червона) – лінія, яка ілюструє якість нашої моделі. Правило таке: чим більше ROC – крива зміщена від діагональної лінії у лівий верхній кут графіка, тим краще.
С. На якість моделі також вказує площа під ROC – кривою (на скріншоті позначено AUC).

Рис. 13. Deductor – площа кривої
Якщо вона більше 0,7 – якість моделі прийнятна, якщо менше – якість моделі недостатня.
І саме головне: ROC – крива показує оптимальну точку відсікання (b). Визначити її можна, натиснувши кнопку  і вивівши на екран значення «баланс» або «максимум» (баланс та максимум – різні методики визначення точки відсікання, вони майже рівні). В нашому випадку оптимальною точкою (порогом) чутливості є значення 0,77- 0,78.
і вивівши на екран значення «баланс» або «максимум» (баланс та максимум – різні методики визначення точки відсікання, вони майже рівні). В нашому випадку оптимальною точкою (порогом) чутливості є значення 0,77- 0,78.
Побудова скорингової моделі на основі нового порогу відсікання (виконайте в DEDUCTOR'і)
1. Знаючи нове оптимальне значення попиту відсікання (візьміть 0,78), побудуйте нову логістичну регресію.
2. Визначте показники її ефективності та порівняйте з попередньою моделлю (зробіть це або в Excel або в Deductor).
3. Також на основі «таблицы сопряженности» визначте грошові втрати кожної логістичної регресії (з порогом 0,5 та 0,78), якщо відомо, що в середньому на кожному хорошому клієнтові, якому відмовила скорингова модель у видачі кредиту (визнала його поганим), ми втратили 1000 грн., а на кожному насправді поганому клієнтові, якому видали кредит (бо скорингова модель визнала його хорошим), ми втрачаємо 5000 грн. (для тих хто шукав показники ефективності моделей в Deductor, то витрати також можна обрахувати в Deductor, для всіх інших – в Excel).
4. Прийміть рішення, яку саме скорингову модель оптимальніше використовувати в діяльності, якщо банк застосовує консервативну стратегію (мінімізація ризиків дефолту).
5. Для вибраної скорингової моделі (для консервативної стратегії) прийміть рішення про видачу кредитів для нових клієнтів у файлі «new_scoring.txt».
При захисті, крім питань, що висвітлені вище, Ви повинні дати відповідь:
1. Як впливає зміна порогу відсікання на рішення скорингової моделі (чого буде більше відхилених чи погоджених кредитів?)
2. Як ринкова ситуація (грошові ресурси дешеві або ж дорогі_ може впливати на встановлення порогу відсікання?
3. Як стратегія банку (наростити кредитний портфель чи максимально вберегти себе від ризиків неповернень) може впливати на встановлення порогу відсікання?