








Лабораторна робота №2, Створення сховищ даних в аналітичній платформі Deductor
Код роботи: 869
Вид роботи: Лабораторна робота
Предмет: Системи підтримки та прийняття рішень (СППР)
Тема: №2, Створення сховищ даних в аналітичній платформі Deductor
Кількість сторінок: 1
Дата виконання: 2015
Мова написання: українська
Ціна: 250 грн
Мета даної лабораторної роботи полягає у вивченні можливостей створення та роботи зі сховищем даних в аналітичній платформі Deductor.
Теоретичні основи роботи
Сховище даних Deductor Warehouse – це спеціально організована база даних, що орієнтована на вирішення завдань аналізу даних і підтримки прийняття рішень, забезпечує максимально швидкий і зручний доступ до інформації.
Deductor Warehouse побудований на моделі ROLAP (схема «сніжинка») і може бути розгорнутий на одній з наступних СУБД:
1. Firebird 1.5 і вище;
2. MS SQL Server 2000 і вище;
3. Oracle починаючи з версії 9i;
Локально база даних Firebird (з використанням бібліотеки fbclient.dll) поставляється разом з Deductor.
Вибір тієї або іншої СУБД для СД часто залежить від багатьох критеріїв: вартість, продуктивність, складність адміністрування тощо.
Можливість роботи зі сховищами даних на СУБД MS SQL Server і Oracle доступна тільки в Deductor Enterprise. Версія програми Deductor Academic підтримує роботу сховища на базі Interbase Firebird.
Призначення сховища даних – своєчасно забезпечити аналітика всією інформацією, необхідною для проведення аналізу, побудови моделей та прийняття рішень. Мета сховища даних – не аналіз даних, а підготовка даних для аналізу та їх консолідація.
В Deductor Warehouse варто виділити наступні об’єкти:
1. Вимір – це послідовність значень одного з параметрів, що аналізується. Наприклад, для параметра «час» це послідовність календарних днів, для параметра «регіон» – список міст. Кожне значення виміру може бути представлене координатою в багатовимірному просторі процесу, наприклад, товар, клієнт, дата.
2. Атрибут – це властивість виміру (тобто точки в просторі). Атрибут допомагає користувачеві повніше описати певний вимір. Наприклад, для виміру «Товар» атрибутами можуть бути «Колір», «Вага», «Габарити».
3. Факт – значення, що відповідає виміру. Факти – це дані, що відображають суть події. Як правило, фактами є числові значення, наприклад, сума і кількість відвантаженого товару, знижка.
4. Посилання на вимір – це встановлений зв’язок між двома і більше вимірами. Річ у тому, що деякі бізнес-терміни (що відповідають вимірам в сховищі даних) можуть утворювати ієрархії, наприклад, «Товари» можуть включати «Продукти харчування» і «Лікарські препарати», які, у свою чергу, поділяються на групи продуктів та ліків тощо. В цьому випадку перший вимір містить посилання на другий, другий – на третій і так далі.
5. Процес – сукупність вимірів, фактів та атрибутів. По-суті, процес і є «сніжинка». Процес описує певну дію, наприклад, продаж товарів, відвантаження, надходження грошових коштів тощо.
6. Атрибут процесу – властивість процесу. Атрибут процесу на відміну від виміру не визначає координату в багатовимірному просторі. Це довідкове значення, що відноситься до процесу, наприклад № накладної, валюта документа тощо. Значення атрибуту процесу на відміну від виміру може бути визначене не завжди.
Часто складно визначитися, що є атрибутом процесу, а що виміром. Універсальних рецептів на всі випадки не існує. Але можна дати загальні рекомендації: сукупність вимірів процесу повинна однозначно визначати єдиний запис в таблиці процесу («точку» в багатовимірному просторі); якщо існують ієрархії, то вибір повинен бути на користь виміру; якщо по об’єкту сховища даних передбачається в майбутньому часто робити «зрізи», то знову краще віддати перевагу виміру.
Наявність можливих пропусків (необов’язкове поле) означає, що об’єкт краще зробити атрибутом процесу.
В Deductor Warehouse може одночасно зберігатися безліч процесів, що мають загальні виміри, наприклад, вимір «Товар», що фігурує в процесах «Прихід» і «Розхід». Всі дані, що завантажуються в СД обов’язково повинні бути визначені як вимір, атрибут або факт (рис. 1).

Рис. 1. Структура сховища даних
Проектування структури сховища даних
Розглянемо приклад проектування сховища даних для процесу продажу товарів в мережі аптек. Є історія продаж різних товарів по днях. Товари об’єднані в групи. Всі дані представлені в 4 таблицях, фрагменти яких представлені нижче:
Таблиця 1
Товарні групи
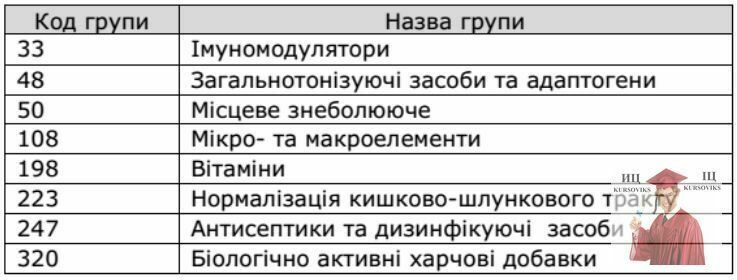
Таблиця 2
Товари (фрагмент)

Таблиця 3
Відділи

Таблиця 4
Продажі (фрагмент)

Тепер визначимося, що в кожній таблиці є фактом, виміром та атрибутом:
1. Таблиця 1: «Код групи» є виміром, «Назва групи» – його атрибутом.
2. Таблиця 2: «Код товару» є виміром, «Назва товару» – його атрибутом, «Код групи» – посиланням на однойменний вимір.
3. Таблиця 3: «Код відділу» є виміром, «Назва відділу» – його атрибутом.
4. Таблиця 4: «Дата» є виміром, «Код відділу» та «Код товару», як було відмічено раніше, – також виміри, «Кількість» та «Сума» – факти.
Програмна реалізація створення сховища даних в Deductor
Послідовність проектування сховища даних не залежить від обраної СУБД, проте єдиною доступною у поставці Academic є InterBase Firebird, на базі якої і буде створено сховище даних. Важливою особливістю є те, що це можна зробити і локально (тобто без фізичної присутності серверу Firebird на ПК). Така можливість забезпечується бібліотекою fbclient.dll, яка є в поставці Academic.
Для початку слід створити власне файл сховища даних, в якому будуть зберігатися всі дані. Файл буде мати розширення .gdb (Gardian Data Base), що є форматом серверу Firebird.
З попередньої лабораторної Вам відомо, що робота в аналітичній платформі Deductor спирається на використання Майстрів. Тому і в даному випадку скористаємося допомогою Майстра підключень. Отож, послідовність наступна:
1. Перейти на закладку «Подключения» (якщо вона відсутня, то скористатися пунктом «Вид – Подключения» або ж кнопкою  ).
).
2. Кнопкою запустити Майстер підключень. Варто зауважити, що список джерел підключень в поставці Academic представлений власне Deductor Warehouse (рис. 2б), а у версії, наприклад, Enterprise значно солідніший (рис. 2б).
Рис. 2а. Джерела підключень в Deductor Academic
Рис. 2б. Джерела підключень в Deductor Enterprise
Кроки Майстра підключень наступні:
a) вибрати Deductor Warehouse як джерело підключень (рис. 2а);
b) вказати шлях до майбутнього файлу сховища даних: натискаємо кнопку ![]() в полі «Базы данных», переходимо у потрібну папку і вводимо (з клавіатури) назву файлу, наприклад «warehouse».
в полі «Базы данных», переходимо у потрібну папку і вводимо (з клавіатури) назву файлу, наприклад «warehouse».
c) логін та пароль – «sysdba» та «masterkey» відповідно, відмітити опцію «Сохранять пароль» (рис. 3а);
d) на наступному кроці – виберіть шосту версію сховища даних;
e) на слідуючому кроці – натиснути кнопку ![]() «Создать файл базы данных с необходимой структурой метаданных» (в результаті буде створений порожній файл СД) та натиснути кнопку
«Создать файл базы данных с необходимой структурой метаданных» (в результаті буде створений порожній файл СД) та натиснути кнопку ![]() «Проверить наличие необходимой структуры метаданных» (рис 3б);
«Проверить наличие необходимой структуры метаданных» (рис 3б);
f) вибрати спосіб візуалізації (рис. 3в);
g) назву СД залишаємо без змін (латиницею), а мітку можна присвоїти будь-яку, в тому числі і на українській мові (рис. 3г).
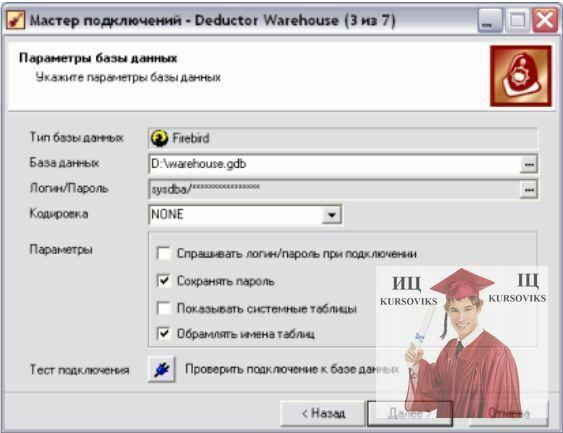
Рис. 3а. Шлях до файлу СД

Рис. 3б. Створення файлу СД
Рис. 3в. Візуалізація СД
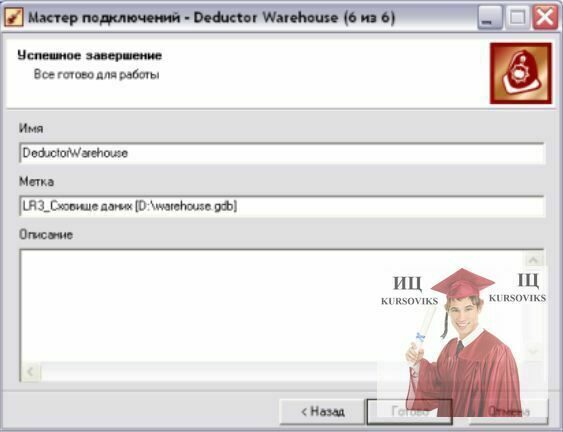
Рис. 3г. Задання назви та мітки СД
В результаті виконаних вище дій у папці, яку Ви вказали на другому кроці, повинен з’явитися відповідний файл СД (з розширенням .gdb). В разі помилкового вказання параметрів сховища змінити їх можна, скориставшись кнопкою ![]() .
.
Очевидно, що сховище даних містить лише необхідні технічні метадані, а бізнес-метадані (назві полів) та бізнес-дані (деталізовані та агреговані) в СД відсутні. Тому наступна наша задача – виправити цей «пробіл».
Наступний крок роботи – створення структури СД.
На даному етапі потрібно чітко визначити, що в нашому СД буде вимірами, а що фактами та атрибутами. Для цього призначений «Редактор метаданных», який викликається кнопкою ![]() . По замовчуванню заборонено змінювати структуру СД. Щоб зняти блокування натисніть кнопку «Разрешить редактирование» (
. По замовчуванню заборонено змінювати структуру СД. Щоб зняти блокування натисніть кнопку «Разрешить редактирование» ( ![]() ) в редакторі метаданих.
) в редакторі метаданих.
Проектування СД здійснимо до прикладу, що був описаний вище.
Для початку за допомогою кнопки додамо перший вимір (измерение) «Код групи» з наступними параметрами: Имя – GR_ID; Мітка – Група.Код; Тип данных – целый. Всі інші параметри – залишаємо по замовчуванню.
При цьому зауважимо, що ім’я – це семантична назва об’єкта СД, яке буде бачити користувач. Аналогічно до цього створимо й інші виміри (табл. 5).
Таблиця 5
Виміри

Для збереження внесених змін натисніть кнопку (рекомендую час від часу натискати цю кнопку). Для продовження редагування структури СД знову натисніть ![]() .
.
В результаті вікно «Редактора метаданих» буде мати наступний вигляд (рис. 4):

Рис. 4. Вікно «Редактор метаданих»
Тепер для кожного виміру, крім «Дата» і «Час», додамо по одному текстовому атрибуту (рис. 5):
- Для виміру «Група.Код» – ім’я «GR_Name», мітка «Група.Найменування».
- Для «Товар.Код» – ім’я «TV_Name», мітка «Товар.Найменування».
- Для «Відділ.Код» – ім’я «PART_Name», мітка «Відділ. Найменування».

Рис. 5. Вікно «Редактор метаданих» на етапі додавання атрибутів для вимірів
Крім того, вимір може посилатися на інший вимір, реалізовуючи таким чином певну ієрархію (в даному випадку «Група товарів – Товар»). Тобто вимір «Товар.Код» посилатиметься на вимір «Группа.Код». Таке посилання задамо в розділі «Измерение» виміру «Товар.Код» (рис. 6).

Рис. 6. Фрагмент вікна «Редактор метаданих» на етапі створення ієрархії вимірів
Після того, як створені виміри та посилання між вимірами, переходимо до створення процесу.
1. Назва процесу – SALES, мітка – Продажи.
2. Виміри: створюються шляхом посилання на раніше створені «Товар.Код», «Відділ.Код», «Дата» і «Час».
3. Факти: кількість (Имя – S_COUNT, Метка – Кількість, Тип данных – Целый) та сума (Имя – S_SUMM, Метка – Сума, Тип данных – Вещественный).
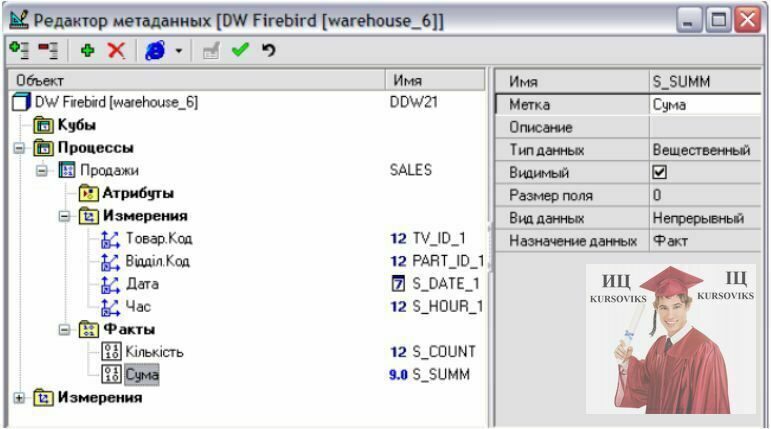
Рис. 7. Вікно «Редактор метаданих» на кінцевому етапі проектування СД
Наповнення сховища даних інформацією
Після проектування структури сховища даних (створення так званого семантичного слою) ми маємо порожнє СД, яке слід наповнити інформацією. Як відомо, в одне і теж сховище даних можна вносити інформацію з різних джерел (баз даних, облікових систем, файлів тощо). Проте функціонал поставки Academic дозволяє в якості джерел даних використовувати лише текстові файли та власне Deductor Warehouse.
В нашій роботі джерелами даних будуть виступати 4 файли: «groups.txt», «produces.txt», «stores.txt» та «sales.txt».
Процес наповнення сховища даних проходить в три етапи:
1. Імпорт даних із файлів в Deductor Studio.
2. Попередня обробка даних, наприклад очистка та перетворення формату (робиться при потребі).
3. Завантаження даних у виміри та процеси в сховище даних Deductor Warehouse.
При завантажені даних безпосередньо в Deductor Warehouse слід зважити на наступні правила:
Перш за все, завантажуються дані у виміри, які мають атрибути. Після цього завантажуються дані в процеси.
Щодо вимірів, то існує правило, згідно якого: завантажувати виміри потрібно із самого верхнього в ієрархії, а потім спускатися нижче. Це дуже важливо, інакше буде порушено ієрархічну цілісність. В нашому випадку спочатку слід завантажити вимір «Групи товарів», а після нього – «Товари».
Допускається не завантажувати виміри, які не мають атрибутів та не знаходяться в ієрархії (в нашому випадку це дата і час). Значення цих вимірів можна створювати пізніше.
Отож, послідовно імпортуймо 4 зазначені вище файли. При імпорті зверніть увагу на:
1. На 3 кроці Майстра імпорту перевіряйте коректність всіх заданих параметрів. При імпорті файлу «sales.txt» можлива помилка (рис. 8). Перегляньте системний журнал, параметри імпорту та власне вміст самого файлу «sales.txt» і подумайте в чому причина такої помилки.

Рис. 8. Вікно повідомлення системного журналу про помилку імпорту
2. На 4 кроці Майстра імпорту уважно слідкуйте і правильно задавайте типи даних для окремих полів (наприклад, Товар.Код, Відділ.Код, Сума тощо).
3. Для зміни параметрів імпорту використовуйте кнопку ![]() .
.
В результаті закладка «Сценарии» матиме наступний вигляд (рис. 9):

Рис. 9. Вікно закладки «Сценарії» після імпорту файлів
Після імпорту файлів перейдемо до завантаження даних в СД, розпочавши з таблиць вимірів і закінчивши таблицею процесу (якщо потрібно, для зміни порядку слідування гілок сценарію використовуйте CTRL+↑ та CTRL+↓).
Завантаження даних в СД Deductor Warehouse здійснюється за допомогою Майстра експорту і проходить в декілька кроків. Наведемо приклад завантаження даних у вимір «Група.Код»:
1. Запустіть Майстер експорту кнопкою  .
.
2. На першому кроці вкажіть, що дані експортуватимуться в СД Deductor Warehouse (рис. 10а).
3. На другому – виберіть потрібне Вам СД – рис. 10б.
4. На третьому – вкажіть об’єкт СД, куди будуть завантажуватися дані (в даному випадку це вимір «Група.Код») – рис. 10в.
5. Переконайтеся чи правильно програма співставила поля в джерелі даних та в СД. Причиною невідповідності полів можуть бути різні типи даних полів в джерелі та СД (рис. 10г).
6. Послідуючі кроки жодних труднощів не представляють, тому завершіть їх самостійно.
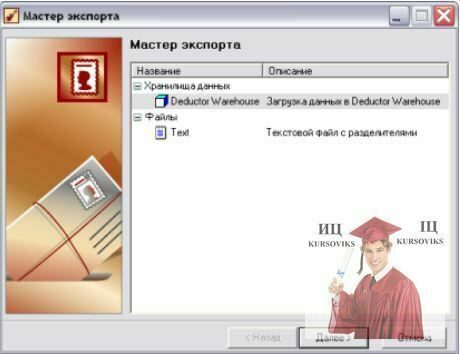
Рис. 10а. Вибір отримувача даних
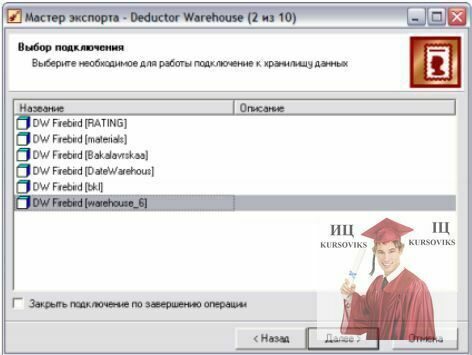
Рис. 10б. Вибір СД
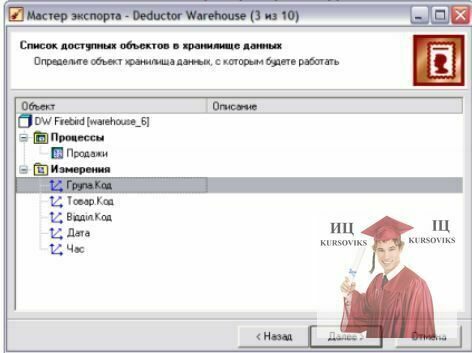
Рис. 10в. Вказання об’єкту СД

Рис. 10г. відповідність полів джерела та СД
Аналогічно, за описаною вище послідовністю, експортуйте дані до сховища у виміри «Товар.Код» та «Відділ.Код» (виміри «Дата» та «Час», як вже зазначалося раніше залишаться поки-що порожніми, оскільки вони не мають атрибутів, і будуть заповнені на слідуючому кроці – заповненні процесу).
Тепер перейдемо до завантаження даних в процес, що також здійснюється за допомогою Майстра експорту. Взагалі дана операція дуже подібна до попередніх, проте тут є два особливих кроки майстра:
1. П’ятий крок – потребує визначення виміру, якому буде вестися контроль за відсутністю дублювань значень у СД. Пояснимо це. Наприклад, в сховищі вже є запис про продажі певного товару по певному відділу за два останні дні і в нових даних, які ми завантажуємо є значення про ці два дні. Тому з метою недопущення дублювання і спотворення даних старі значення будуть видалені, а на їхнє місце будуть записані нові. Для цього і ставиться опція «Дата» (рис. 11).
2. На шостому та сьомому кроках слід залишити все без змін.

Рис. 11. П’ятий крок Майстра експорту на етапі заповнення даними процесу «Продажи»
Кінцевий вигляд фрагменту вікна на закладці «Сценарії» зображено на рис. 12.

Рис. 12. Фрагмент вікна закладки «Сценарії»
Завершальним етап нашої роботи буде отримання даних зі СД в потрібному нам вигляді.
Вирішується дана задача за допомогою Майстра імпорту.
Наприклад, нам потрібно отримати дані про продаж груп товарів за останній місяць від наявних в нас даних по всім трьох аптеках. Для цього:
1. Запустіть Майстер імпорту.
2. Вкажіть, що імпорт буде здійснюватися з потрібного СД.
3. Вкажіть, що будуть оброблятися дані з процесу «Продажи».
4. На 4 кроці слід уважно відмітити об’єкти, які потрібно імпортувати з СД. В нашому випадку це: «Група.Найменування», «Відділ. Найменування», «Дата» та «Сума» (рис. 13).

Рис. 13. Вибір вимірів для імпорту
5. На 5 кроці слід вибрати фільтр для даних. Звичайно таке фільтрування можна провести і пізніше, але доцільність цієї дані саме на даному етапі зумовлюється суттєвою економією часу імпорту. Отож, навпроти виміру «Дата» в колонці «Условие» вибираємо значення «последний», а в колонці «Значение» вказуємо «месяц от имеющихся данных» (рис. 14).

Рис. 14. П’ятий крок Майстра імпорту на етапі отримання даних із СД
6. На подальших кроках майстру жодних проблем виникнути не повинно.
В результаті вікно сценаріїв буде мати наступний вигляд (рис. 15):

Рис. 15. Вікно закладки «Сценарії»
За допомогою Майстра обробка викличте обробник «Настройка набора данных» та задайте більш змістовні назви полів (наприклад не «Товар.Код| Товар.Найменування», а «Товар»
Отож, виконавши дану роботу ми навчилися:
1. Проектувати структуру СД.
2. Заповнювати СД із текстових файлів.
3. Отримувати дані із СД в потрібному нам аналітичному зрізі.
Збережіть файл сценарію під назвою «lr2.ded» у власній папці. При закритті програми збережіть всі наявні підключення.
Завдання для самостійної роботи:
За допомогою Майстра імпорту виберіть зі СД наступні дані:
1. продажі за останній місяць від наявних даних по всім аптеках засобу «Аспирин плюс C табл.раствор. 10 BIFA, Bayer» – у табличній та графічній формі (16а,б);
2. загальні обсяги продаж по трьох аптеках – в табличній формі та у вигляді кругової діаграми (16в,г);
3. динаміку продаж засобів групи «Витамины и витаминоподобные средства» за останній місяць наявних даних по Аптеці 3 – в табличній формі та за допомогою стовпчикової діаграми (16д,е).

