Лабораторна робота №1, Статистичне прогнозування макроекономічних показників із використанням моделей кривих підгонки та ex-post прогнозування
Код роботи: 2594
Вид роботи: Лабораторна робота
Предмет: Прогнозування соціально-економічних процесів (ПСЕП)
Тема: №1, Статистичне прогнозування макроекономічних показників із використанням моделей кривих підгонки та ex-post прогнозування - Варіант №14
Кількість сторінок: 1
Дата виконання: 2017
Мова написання: українська
Ціна: 150 грн (за файл-Excel)
Мета: набути практичні навички побудови кривих підгонки на основі статистичних рядів даних та вибору моделі прогнозування із застосуванням EX-POST прогнозування.
Хід роботи
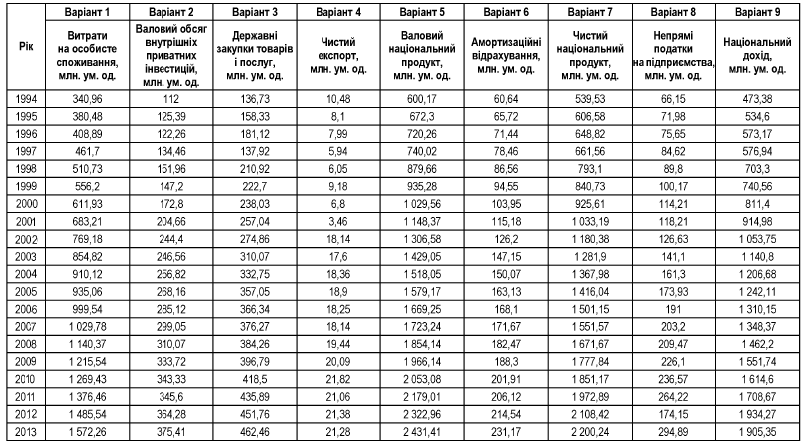
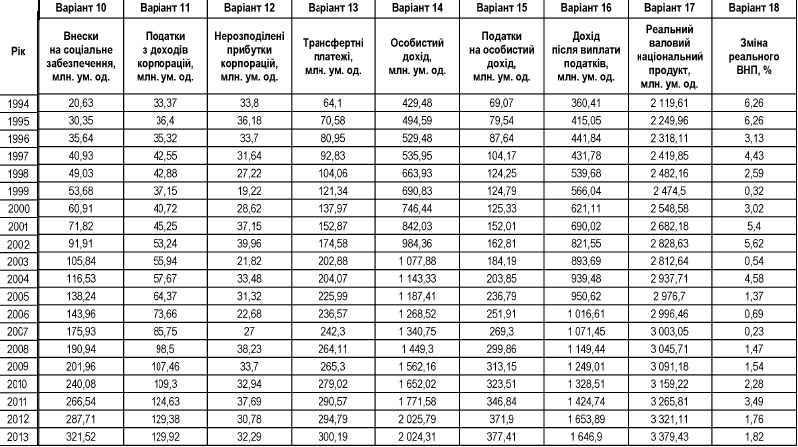
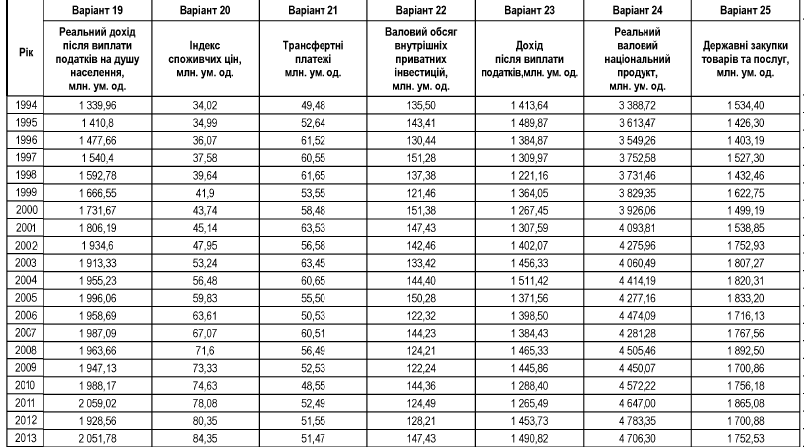
Завдання 1. Для економічних показників країни за 1994-2013 роки у відповідності до варіанту розробити моделі шляхом підбору кривої підгонки, виконати верифікацію моделей і обрати найкращу для прогнозування модель. Вибір обґрунтувати. Створити точковий та інтервальний прогноз на 2014 рік.
Методичні рекомендації щодо виконання
1. Для вирішення завдання спочатку треба обрати показник відповідно до свого варіанта. Потім побудувати таблицю (див. нижче) в документі Excel, в якій ввести конкретну назву показника і його фактичні значення відповідно до року.
|
MОДЕЛЬ 1 (ОПИС) |
Показник «НАЗВА ПОКАЗНИКА» |
|||
|
Рік |
Yі Фактичні значення (одиниця вимірювання) |
Ŷі Обчислені за моделлю значення (одиниця вимірювання) |
еі Похибка (одиниця вимірювання) |
еі/Yі Відносна похибка
|
|
1994 |
|
|
|
|
|
1995 |
|
|
|
|
|
1996 |
|
|
|
|
|
1997 |
|
|
|
|
|
1998 |
|
|
|
|
|
1999 |
|
|
|
|
|
2000 |
|
|
|
|
|
2001 |
|
|
|
|
|
2002 |
|
|
|
|
|
2003 |
|
|
|
|
|
2004 |
|
|
|
|
|
2005 |
|
|
|
|
|
2006 |
|
|
|
|
|
2007 |
|
|
|
|
|
2008 |
|
|
|
|
|
2009 |
|
|
|
|
|
2010 |
|
|
|
|
|
2011 |
|
|
|
|
|
2012 |
|
|
|
|
|
2013 |
|
|
|
|
|
å |
|
|
|
|
|
2014 |
|
Точковий прогноз |
|
|
|
R2 |
Вивести при побудові лінії тренду |
|||
|
MSE |
формула |
|||
|
RMSE |
Формула |
|||
|
MAD |
Формула |
|||
|
MRSPE |
Формула |
|||
|
MAPE |
Формула |
|||
|
Висновки |
Текст висновків |
|||
2. Після цього необхідно побудувати діаграму (графік або гістограму) функціональної залежності значень показника за роками. Діаграми треба будувати без урахування прогнозованого року. На побудованій діаграми треба додати лінію тренду – лінійну криву підгонки. Відобразити рівняння регресії – функцію підгонки та коефіцієнт детермінації R2. Знайти точковий прогноз на 2014 рік. Після цього виконати у таблиці необхідні розрахунки значень оцінок.
Скористатись формулами:
 ,
,
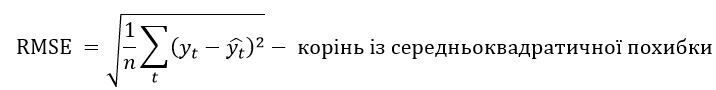
прогнозу за n кроків.
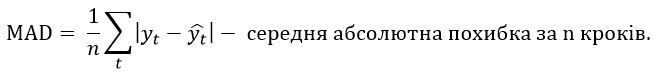
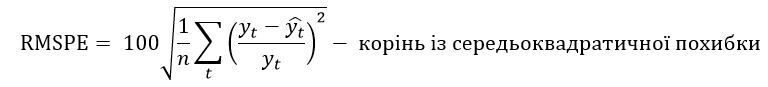
у відсотках від фактичних значень за n кроків.

На практиці ці характеристики використовуються досить часто. Перші три критерії виражають похибку у одиницях виміру, тому їх величина залежить від специфіки часового ряду. Останні два критерії вимірюються у відносних одиницях, тому можна говорити про деякий загальний рівень адекватності моделі на основі їх порівняння. Чим меншою є величина критерію похибки, тим краще побудована модель для прогнозування.
3. Аналогічно побудувати ще квадратичну, експоненціальну, логарифмічну, степеневу поліноміальну третього степеня функції підгонки. Виведіть на діаграму рівняння регресії та значення коефіцієнта детермінації. Оберіть з отриманих рівнянь регресії ті, які можна використати для прогнозування. Для обраних функцій регресії розробіть таблиці, аналогічні до таблиці пункту 1. Порада: скопіюйте таблицю, створену у пунктах 1-2 і виправте значення 2 і 3 стовпців.
4. Скласти порівняльну таблицю і зробити висновки. Обрати найкращу модель для прогнозування.
|
ПОРІВНЯЛЬНА ТАБЛИЦЯ МОДЕЛЕЙ |
||||||
|
|
R2 |
SE |
RMSE |
MAD |
MRSPE |
MAPE |
|
Модель 1 |
|
|
|
|
|
|
|
Модель 2 |
|
|
|
|
|
|
|
Модель 3 |
|
|
|
|
|
|
5. Далі визначити довірчий 95%-ний інтервал за допомогою інструмента «Описова статистика» з пакета «Аналіз даних» або вбудованих функцій.
Інтервал прогнозування знаходимо таким чином:

Інтервальний прогноз (Ymin; Ymax).
6.Важливим етапом статистичного прогнозування є верифікація прогнозів, тобто оцінювання їх точності та обґрунтованості. Ha етапі верифікації використовують сукупність критеріїв, способів і процедур, які дають можливість оцінити якість прогнозу.
Найбільш поширене ретроспективне оцінювання прогнозу, тобто оцінювання прогнозу для минулого часу (ex-post прогноз). Процедура перевірки така. Динамічний ряд поділяється на дві частини:
- перша — для t = 1,2,3, ...,p — називається ретроспекцією (передісторією),
- друга — для t= p + 1, p + 2, p + 3, ..., p +(n —р) — прогнозним періодом.
За даними ретроспекції моделюється закономірність динаміки і на основі моделі розраховується прогноз Yp+v, де v — період упередження. Ретроспекція послідовно змінюється, відповідно змінюється прогнозний період, що унаочнює рис. 1 (для v = 1).

Рис. 1 - Схема ретроспективної перевірки точності прогнозу для v = 1
Оскільки фактичні значення прогнозного періоду відомі, то можна визначити похибку прогнозу як різницю фактичного уt і прогнозного ŷt рівнів: et = yt – ŷt. Всього буде n —р похибок.
Узагальнюючою оцінкою точності прогнозу слугує середня похибка:
абсолютна  , квадратична
, квадратична  .
.
Ідея ex-post прогнозу. Початкові дані розбиваються на дві групи, так щоб в другій групі знаходилися пізніші дані, що становлять зазвичай приблизно 15% всієї інформації. Ці дані будуть потім використовуватися для тестування. При невеликому об'ємі початкових даних в другій групі можна розглядати до 30% початкової інформації.
Але спочатку ми повинні задати горизонт прогнозування. При цьому кожного разу ми порівнюватимемо набуті значення з наявною інформацією. У цьому якраз і полягає головна перевага ex-post прогнозування. При звичному прогнозуванні у нас такої можливості немає.
Алгоритм ex-post прогнозування:
1. Ділимо вибірку з n значеннями на 2 частини: 80% (р значень) та 20 % (n-p значень). З отриманих попередньо результатів обираємо криву підгонки, яка є найбільш ефективною для прогнозування.
2. З рівняння кривої підгонки визначаємо прогнозне значення показника на р+1-й період.
3. Порівнюємо одержаний прогноз з фактичним значенням показника за р+1-й період, знаходимо помилку прогнозу.
4. Повторюємо пункти 1-3 послідовно для р+1, р+2, … , n-p значень.
5. Розраховуємо ē, s та коефіцієнт нерівності Тейла. Коефіцієнт нерівності Тейла розраховуємо за формулою:

де Т = n-k – кількість ex-post прогнозів.
В результаті ми одержуємо таблицю, що містить ex-post прогнози і відповідні помилки для n-p прогнозів
|
Рік |
Yі |
Ŷі |
еі |
еі/ Yі |
|
р+1 |
|
|
|
|
|
р+2 |
|
|
|
|
|
…. |
|
|
|
|
|
n-p |
|
|
|
|
|
å |
|
|
|
|
|
ē |
|
|||
|
s |
|
|||
|
Kоефіцієнт Тейла |
|
|||
Зробити висновки стосовно точності та обґрунтованості прогнозної моделі.
Завдання 2. Скласти звіт у файлі Zvit1_Прізвище.doc. Захистити виконану роботу.
Перелік питань для самоконтролю
1. Дати означення прогнозу.
2. Дати означення економічного прогнозування.
3. Що є метою економічного прогнозування?
4. Дати означення об’єкта прогнозування.
5. Дати означення предмета прогнозування.
6. Як взаємопов’язані прогноз, план, управління?
7. Що собою являє економічний проноз?
8. Дати означення системи взагалі.
9. Охарактеризувати властивості системи.
10. Дати означення соціально-економічної системи.
11. Дати означення системи соціально-економічного прогнозування.
12. Перерахувати вимоги до системи соціально-економічного прогнозування.
13. Охарактеризувати вимогу до системи соціально-економічного прогнозування з позиції «чорного ящика».
14. Назвати всі вимоги забезпечення конкурентноспромоності товару.
15. Дати класифікацію прогнозів залежно від характеру об’єкту.
16. Дати класифікацію прогнозів залежно від часу випередження.