








Лабораторна робота №10, Використання інструментів fill from example і forecast
Код роботи: 2514
Вид роботи: Лабораторна робота
Предмет: Інтелектуальний аналіз данних
Тема: №10, Використання інструментів fill from example і forecast
Кількість сторінок: 11
Дата виконання: 2017
Мова написання: українська
Ціна: 250 грн (+ програма)
Мета: Розглянути використання інструментів «FILLFROM EXAMPLE» і «FORECAST»
Хід роботи
Обидва розглянутих інструменти використовуються для вирішення задач прогнозування невідомих значень параметрів. Тому в обох випадках потрібно навчальний набір даних, на базі якого будується модель, яка застосовується для передбачення.
Заповнення за прикладом
В якості досліджуваного набору даних, буде використовуватися той же локалізований приклад для Excel, що і в минулій лабораторній. Потрібні дані знаходяться на аркуші «Заполнение из примера» (рис. 1).

Рис. 1 - Набір даних для інструмента Fill From Example
Набір даних описує ряд клієнтів магазину. Для деяких з них відзначено, чи є даний клієнт «високоприбутковим» чи ні. Ці рядки будуть використовуватися як навчальна вибірка. Завданням аналізу буде оцінка інших клієнтів по цьому параметру.
Для вирішення цього завдання використовується алгоритм Microsoft Logistic Regression. Для створення моделі в навчальній вибірці повинні бути представлені варіанти з усіма можливими значеннями цільового стовпця. Як правило, чим більше характерних прикладів в навчальній вибірці, тим більш якісною буде навчена модель.
Даний інструмент непридатний для задачі передбачення значень параметра, який може приймати безперервні числові значення.
Ще одна особливість - аналіз проводиться за стовпцями (тобто передбачається значення стовпця). Якщо ряд, який необхідно заповнити, зберігається у вигляді рядка, перед початком аналізу треба виконати транспонування (скопіювати в буфер, вибрати в контекстному меню
«Специальная вставка» і відзначити прапорець «Транспонировать»).
Запустимо інструмент Fill From Example. У першому вікні буде запропоновано вибрати стовпець, що містить зразки даних. У нашому випадку він автоматично визначений вірно – «Высокодоходный клиент». Як і в попередніх випадках, за посиланням «Choose columns to beused for analysis», можна вибрати стовпчики, що враховуються при аналізі. Евристичний механізм визначив, що поле ID враховувати не треба. На практиці, рекомендовані настройки варто міняти тільки у випадку, якщо точно відомо про взаємну незалежність параметрів.
Після запуску, інструмент формує звіт про виявлені шаблони (рис. 2),
і додає стовпець з передбаченими значеннями до вихідної таблиці.
У звіті описуються виявлені залежності між значенням цільового стовпця і значеннями інших стовпців.
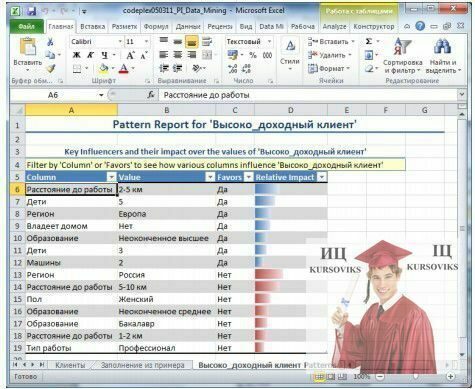
Рис. 2 - Звіт про виявлені шаблоні
На рис. 2 видно, що значення параметра «Расстояние до работы» рівне «2-5 км» має найбільшу питому вагу при виборі варіанту «Да». Це можна інтерпретувати, як «відстань 2-5 км до роботи багато в чому визначає вибір на користь покупки велосипеда».
Для кожного рядка розраховується підсумкова оцінка для кожного варіанту (у прикладі - для «Да» і «Нет») і робиться вибір на користь значення з найбільшою сумарною питомою вагою. Воно заноситься в стовпець з суфіксом «_Extended» (на рис. 28 «Высоко_доходный клиент_Extended»). Для записів, на яких модель навчалася, значення цього стовпця збігається із зразком.
Припустимо, ми отримали додаткові дані про якихось клієнтів. Можна змінити зразок (рис. 3, останній рядок) і знову запустити інструмент. Нові значення будуть отримані з урахуванням уточнень в наборі навчальних даних. Подібні ітерації дозволяють послідовно уточнювати оцінку значень.

Рис. 3 - Отримані оцінки заносяться у вихідну таблицю
Завдання 1. Проведіть аналіз, аналогічний описаному вище, і прокоментуйте отримані результати. Змініть навчальний набір даних таким чином: знайдіть рядок зі значенням «расстояние до работы 2-5 км», (наприклад, рядок з ідентифікатором 19562, 97-й рядок у таблиці) і для параметра «Высокодоходный клиент» поставте значення «Нет». Повторіть аналіз. Як змінився звіт про шаблони ? Поясніть ці зміни.
Для того, щоб повністю видалити результати роботи інструменту, достатньо видалити аркуш із звітом і доданий стовпець у таблиці з вихідними даними.
Прогноз
Інструмент Forecast дозволяє побудувати прогноз значень числового ряду. Ряд повинен бути представлений стовпцем в таблиці (якщо досліджувані значення організовані у вигляді рядка, потрібно, як і у випадку інструменту «Fill From Example», виконати транспонування).
У використовуваному нами файлі Excel на аркуші «Прогнозирование» є набір даних за сумами продажів велосипедів марки М200 по місяцях в трьох різних регіонах. Таким чином, для дослідження ми маємо три числові послідовності, можливо пов'язані між собою (рис. 4).

Рис. 4 - Зразок даних для прогнозування - продажу по місяцях велосипедів моделі M200 в різних регіонах
У процесі роботи інструмент будує модель з використанням алгоритму часових рядів (Microsoft Time Series). Для його роботи необхідно, щоб в досліджуваних стовпцях були тільки числа, пропуски допустимі. Передбачати можна безперервні числові або грошові (тип currency) значення. Інструмент не розрахований на передбачення дат.
Інструмент шукає в аналізованій послідовності шаблони наступних типів:
1) тренд - тенденція зміни значень. Тренд може бути висхідним (зростання значень ряду) або низхідним (зменшення значень);
2) періодичність (сезонність) - подія повторюється через визначені інтервали;
3) взаємна кореляція - залежність значень одного ряду від інших (наприклад, вартість акцій нафтових компаній від цін на нафту). Алгоритми, які виявляють взаємну кореляцію, входять в поставку MS SQL Server 2008 версії Enterprise або Developer, а у версії Standard недоступні.
Налаштування параметрів полягає у виборі аналізованих стовпців, кількості прогнозованих значень ряду, вказівки тимчасової оцінки і типу періодичності (рис. 5).
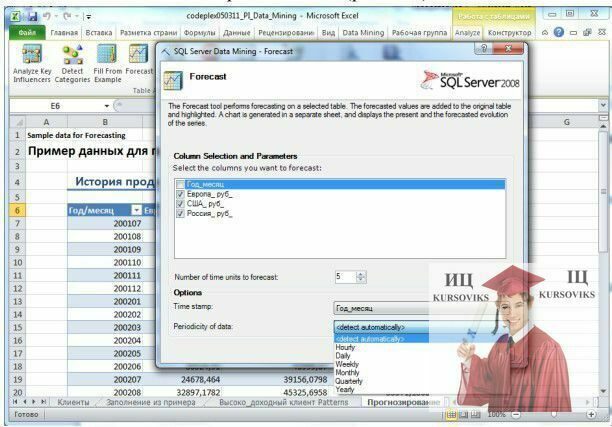
Рис. 5 - Налаштування параметрів інструменту Forecast
У нашому випадку, в якості позначки часу логічно вибрати поле «Год / месяц» (інструмент змінив його назву на «Год_месяц» для сумісності з вимогами SQL Server) і погодитися з виключенням його зі списку прогнозованих. Треба відзначити, що значення в стовпці, що використовується як тимчасова мітка, повинні бути унікальні.
Що стосується періодичності, то пропоновані для вибору варіанти визначаються таким чином:
- Hourly (погодинна) - шукається періодичність 12;
- Daily (денна) - шукається періодичність 5 і 7 (робочі дні і тиждень повністю);
- Weekly (тижнева) - 4 і 13 (число тижнів у місяці та кварталі);
- Monthly (місячна) - 12 (кількість місяців у році);
- Yearly - інструмент буде автоматично виявляти періодичності.
Якщо періодичність невідома, то рекомендується залишити «detect automatically», щоб інструмент перевірив дані на наявність періодичності різних типів.
За результатами аналізу створюється звіт з графіком (рис. 6), на якому безперервною линією позначений «історичний тренд», побудований за наявними значеннями. Пунктирною лінією показано прогнозоване продовження тренда. Зверніть увагу, що тимчасові мітки для спрогнозованих значень не проставлено.
У вихідну таблицю будуть додані результати прогнозу (стільки значень, скільки було вказано при запуску - рис. 5).
На малюнку 32 додані значення виділені кольором фону. Щоб продовжити ряд тимчасових міток, можна виділити кілька останніх значень стовпця «Год/месяц» і незаповнену область в рядках з прогнозом, вибрати на панелі управління у стрічці «Главная» кнопку «Заполнить» (на рис. 7 підкреслена), зі списку вибрати варіант «Прогрессия» і вказати автоматичне визначення кроку. Відсутні значення будуть додані. Тепер і на графіку будуть автоматично проставлені відсутні тимчасові мітки.
Щоб прибрати результати роботи інструменту, треба видалити аркуш звіту і рядки вихідної таблиці з новими значеннями.
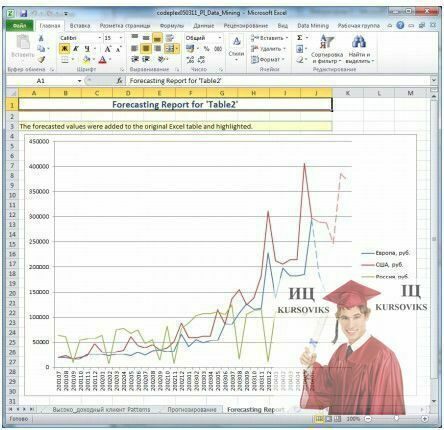
Рис. 6 - Звіт інструмента Прогноз

Рис. 7 - Передбачені значення і заповнення стовпця з мітками
Завдання 2. За допомогою інструменту Forecast побудуйте прогноз продажів на рік (12 значень). Проаналізуйте графік. На ваш погляд, який тип періодичності виявив інструмент у вихідних даних і використовує для передбачення?